Yummy - delicious Feast extension
04 May 2022
In this article I’d like to present a really delicious Feast extension Yummy.
Before you will continue reading please watch short introduction:
Last time I showed the Feast integration with the Dask framework which helps to distribute ML solutions across the cluster but doesn’t solve other problems. Currently in Feast we have a warehouse based approach where Feast builds and executes query appropriate for specific database engines. Because of this architecture Feast can’t use multiple data sources at the same time. Moreover the logic which fetch historical features from offline data sources is duplicated for every datasource implementation which makes it difficult to maintain.
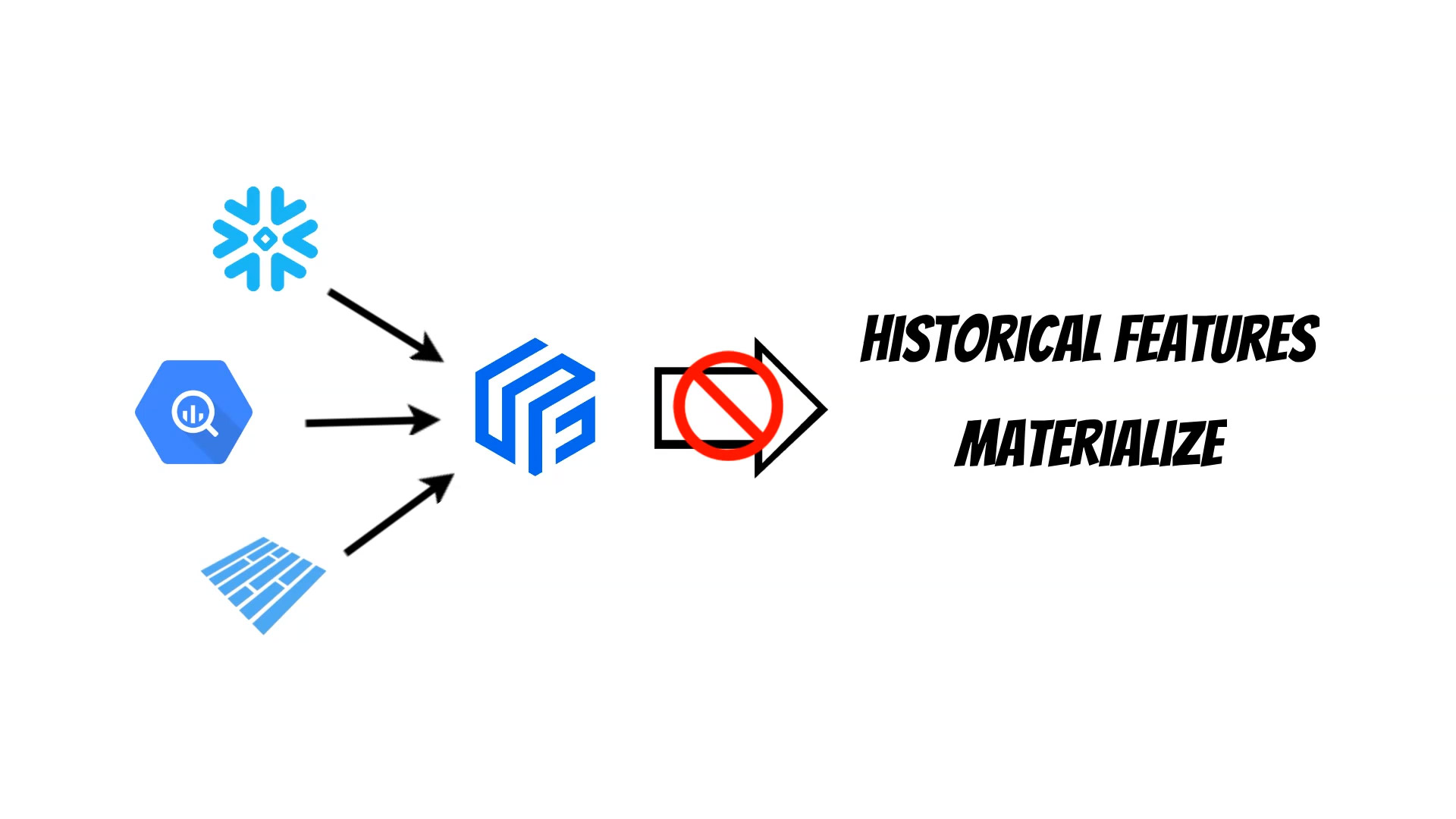
To solve this problems I have decided to create Yummy Feast extension, which is also published as a pypi package.
In Yummy I have used a backend based approach which centralizes the logic which fetches historical data from offline stores. Currently: Spark, Dask, Ray and Polars backends are supported. Moreover because the selected backend is responsible for joining the data we can use multiple different data sources at the same time.
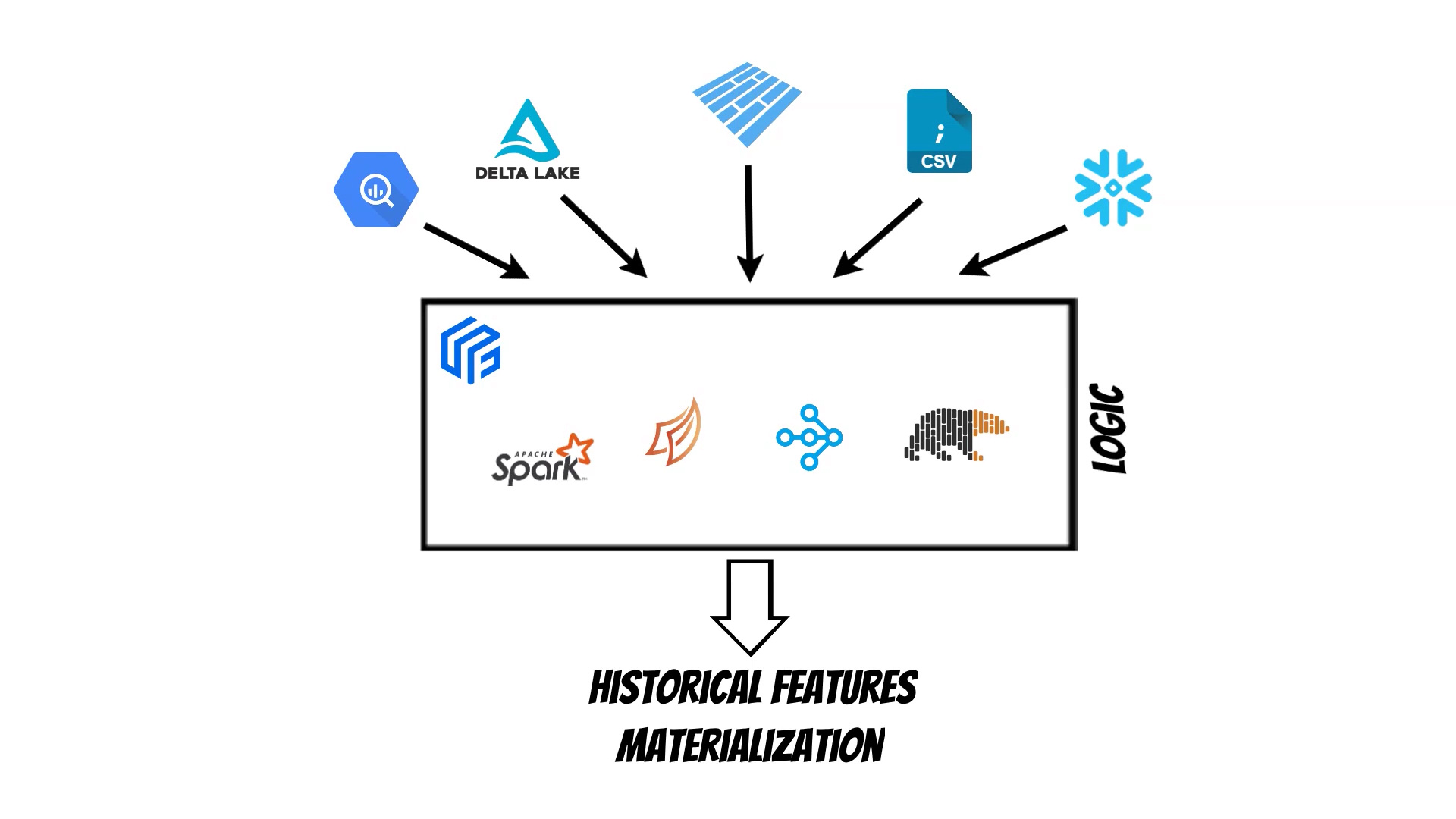
Additionally with Yummy we can start using a feature store on a single machine and then distribute it using the selected cluster type. We can also use ready to use platforms like: Databricks, Coiled, Anyscale to scale our solution.
To use Yummy we have to install it:
pip install yummy
Then we have to prepare Feast configuration feature_store.yaml:
project: repo
registry: s3://feast/data/registry.db
provider: local
online_store:
type: redis
connection_string: "redis:6379"
offline_store:
type: yummy.YummyOfflineStore
backend: dask
In this case we will use s3 as a feature store registry and redis as an online store.
The Yummy takes offline store responsibility and in this case we have selected
dask backend.
For dask, ray and polars backends we don’t have to set up the cluster to
work. In this case if we don’t provide cluster configuration they will run
locally. For Apache Spark additional configuration is required for local machines.
In the next step we need to provide feature store definition in the python file eg. features.py
from google.protobuf.duration_pb2 import Duration
from feast import Entity, Feature, FeatureView, ValueType
from yummy import ParquetDataSource, CsvDataSource, DeltaDataSource
my_stats_parquet = ParquetDataSource(path="/mnt/dataset/all_data.parquet", event_timestamp_column="datetime",)
my_stats_delta = DeltaDataSource(path="/mnt/dataset/all/", event_timestamp_column="datetime",)
my_stats_csv = CsvDataSource(path="/mnt/dataset/all_data.csv", event_timestamp_column="datetime",)
my_entity = Entity(name="entity_id", value_type=ValueType.INT64, description="entity id",)
mystats_view_parquet = FeatureView(name="my_statistics_parquet", entities=["entity_id"], ttl=Duration(seconds=3600*24*20),
features=[
Feature(name="f0", dtype=ValueType.FLOAT),
Feature(name="f1", dtype=ValueType.FLOAT),
Feature(name="y", dtype=ValueType.FLOAT),
], online=True, input=my_stats_parquet, tags={},)
mystats_view_delta = FeatureView(name="my_statistics_delta", entities=["entity_id"], ttl=Duration(seconds=3600*24*20),
features=[
Feature(name="f2", dtype=ValueType.FLOAT),
Feature(name="f3", dtype=ValueType.FLOAT),
], online=True, input=my_stats_delta, tags={},)
mystats_view_csv = FeatureView(name="my_statistics_csv", entities=["entity_id"],
ttl=Duration(seconds=3600*24*20),
features=[
Feature(name="f11", dtype=ValueType.FLOAT),
Feature(name="f12", dtype=ValueType.FLOAT),
], online=True, input=my_stats_csv, tags={},)
In this case we have used three Yummy data sources: ParquetDataSource, DeltaDataSource,
CsvDataSource. Before I have generated three data sources:
- parquet file (
/mnt/dataset/all_data.parquet) - delta lake (
/mnt/dataset/all/) - csv file (
/mnt/dataset/all_data.csv)
Currently Yummy won’t work with other Feast data sources like BigQuerySource or RedshiftSource.
Then we can apply our feature store definition and keep it on s3:
feast apply
Now we are ready to fetch required features from defined stores. To do this we simply run:
from feast import FeatureStore
import time
store = FeatureStore(repo_path='.')
start_time = time.time()
training_df = store.get_historical_features(
entity_df=edf,
features = [
'my_statistics_parquet:f0',
'my_statistics_parquet:f1',
'my_statistics_parquet:y',
'my_statistics_delta:f2',
'my_statistics_delta:f3',
'my_statistics_csv:f11',
'my_statistics_csv:f12',
]
).to_df()
print("--- %s seconds --- " % (time.time() - start_time))
training_df
We have started with the dask backend but we can simply switch to ray
changing feature_store.yaml configuration to:
project: repo
registry: s3://feast/data/registry.db
provider: local
online_store:
type: redis
connection_string: "redis:6379"
offline_store:
type: yummy.YummyOfflineStore
backend: ray
or to polars backend (which is currently the fastest option):
project: repo
registry: s3://feast/data/registry.db
provider: local
online_store:
type: redis
connection_string: "redis:6379"
offline_store:
type: yummy.YummyOfflineStore
backend: polars
we can also use spark cluster where additional configuration options are
available (they are used during spark session initialization):
project: repo
registry: s3://feast/data/registry.db
provider: local
online_store:
type: redis
connection_string: "redis:6379"
offline_store:
type: yummy.YummyOfflineStore
backend: spark
config:
spark.master: "local[*]"
spark.ui.enabled: "false"
spark.eventLog.enabled: "false"
spark.sql.session.timeZone: "UTC"
Finally we can materialize data from offline stores to online store using preferred backend:
feast materialize 2020-01-03T14:30:00 2023-01-03T14:30:00
Yummy solves several Feast limitations:
