Text transmutation - recipe for semantic search with embeddings
31 Dec 2023
In the rapidly evolving area of data science and natural language processing (NLP), the ability to intelligently understand and process textual information is crucial. In this article I will show how to create a semantic search aplication using the Candle ML framework written in Rust, coupled with the E5 model for embedding generation.
Before you will continue reading please watch short introduction:
Text embeddings are at the heart of modern natural language processing (NLP). They are the result of transforming textual data into a numerical form that machines can understand.
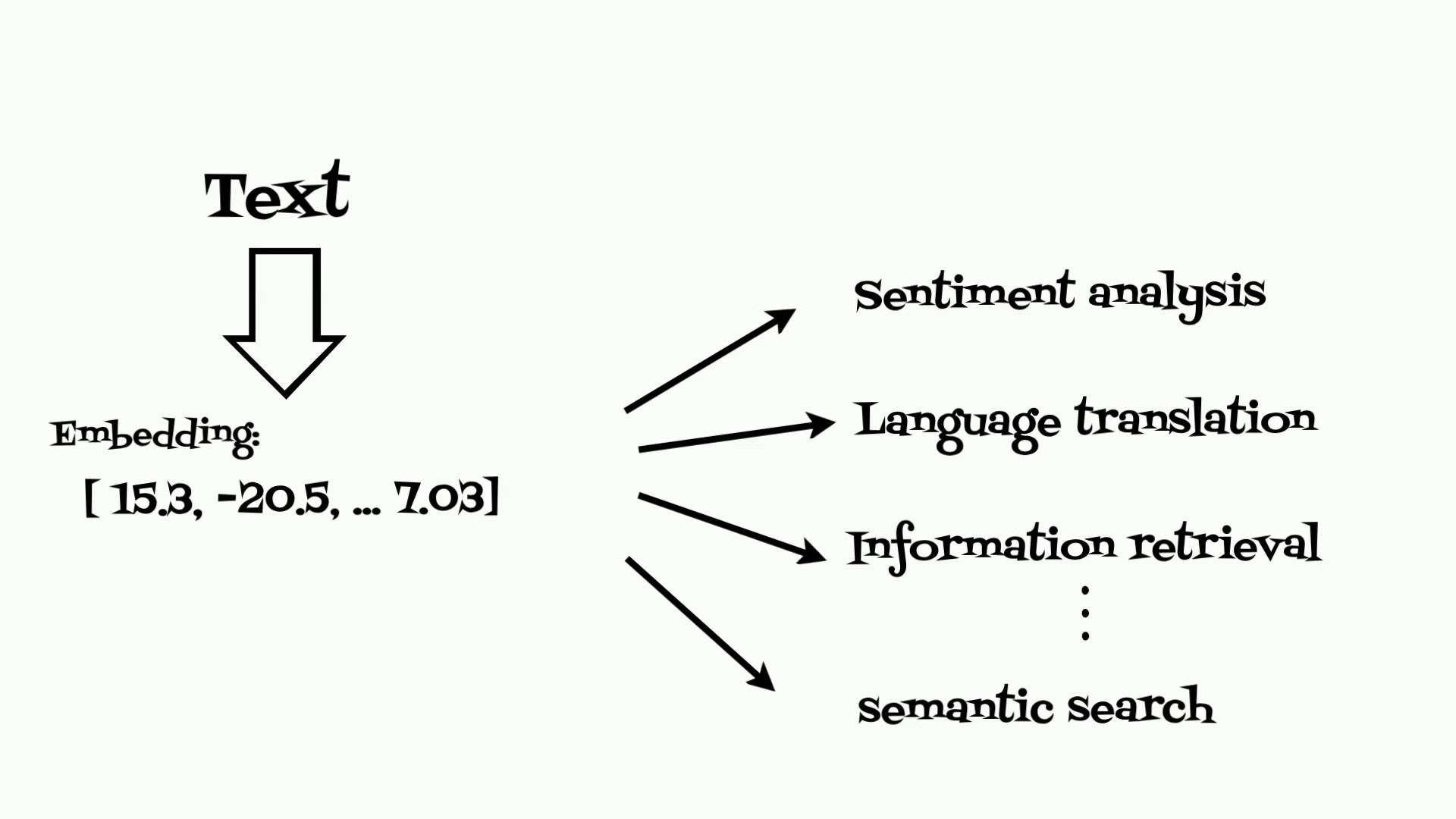
To calculate embeddings I will use the E5 model (arxiv2212.03533) from Hugging Face to generate text embeddings.
E5 name comes from embeddings from bidirectional encoder representations. Model was trained on Colossal Clean text Pairs from heterogeneous semi-structured data sources like: Reddit (post, comment), Stackexchange (question, upvoted answer), English Wikipedia (entity name + section title, passage), Scientific papers (title, abstract), Common Crawl (title, passage), and others.
To run the E5 model I will use the Candle ML framework written in Rust. Candle supports a wide range of ML models including: Whisper, LLama2, Mistral, Stable Diffusion and others. Moreover we can simply compile and use Candle library inside WebAssembly to calculate text embeddings.
To demonstrate the power of these embeddings, I have created a simple search application. The application contains two parts: rust code which is compiled to WebAssembly and Vue web application.
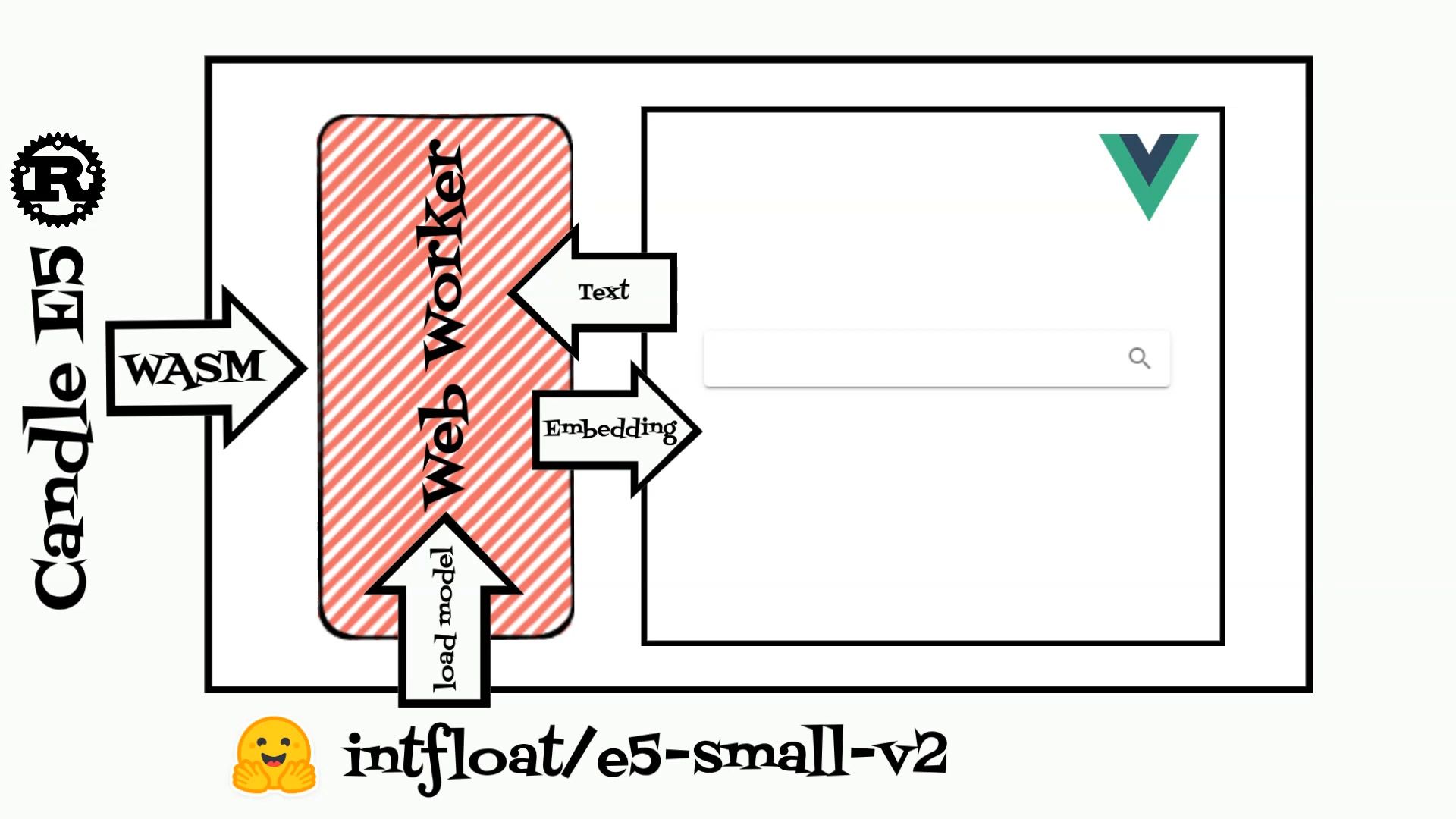
The rust code is based on the candle Web Assembly example and expose model struct which loads the E5 model and calculates embeddings. Compiled rust struct is used in the Vue typescript webworker.
The web application reads example recipes and calculates embeddings for each.
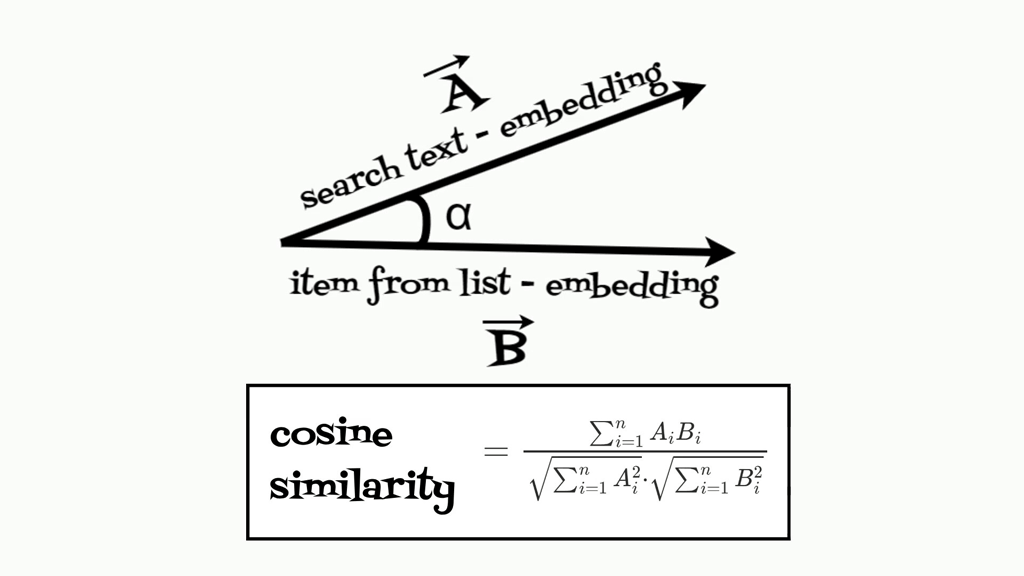
When user inputs a text application calculates embedding and search the recipe from the list that matches the best, the cosine similarity is used for this purpose.
Cosine similarity measures the cosine of the angle between two vectors, offering a way to judge how similar two texts are in their semantic content.
For handling larger datasets, it becomes impractical to compute cosine similarity for each phrase individually due to scalability issues. In such cases, utilizing a vector database is a more efficient approach.
Application code is available here: https://github.com/onceuponai-dev/stories-text-transmutation The rust part is based on Candle example
You can also quickly test model on: https://stories.onceuponai.dev/stories-text-transmutation/