Distributed Feature Store with Feast and Dask
12 Nov 2021
In this article I will show how we combine Feast and Dask library to create distributed feature store.
Before you will continue reading please watch short introduction:
The Feature Store is very important component of the MLops process which helps to manage historical and online features. With the Feast we can for example read historical features from the parquet files and then materialize them to the Redis as a online store.
But what to do if historical data size exceeds our machine capabilities ? The Dask library can help to solve this problem. Using Dask we can distribute the data and calculations across multiple machines. The Dask can be run on the single machine or on the cluster (k8s, yarn, cloud, HPC, SSH, manual setup). We can start with the single machine and then smoothly pass to the cluster if needed. Moreover thanks to the Dask we can read bunch of parquets using path pattern and evaluate distributed training using libraries like scikit-learn or XGBoost
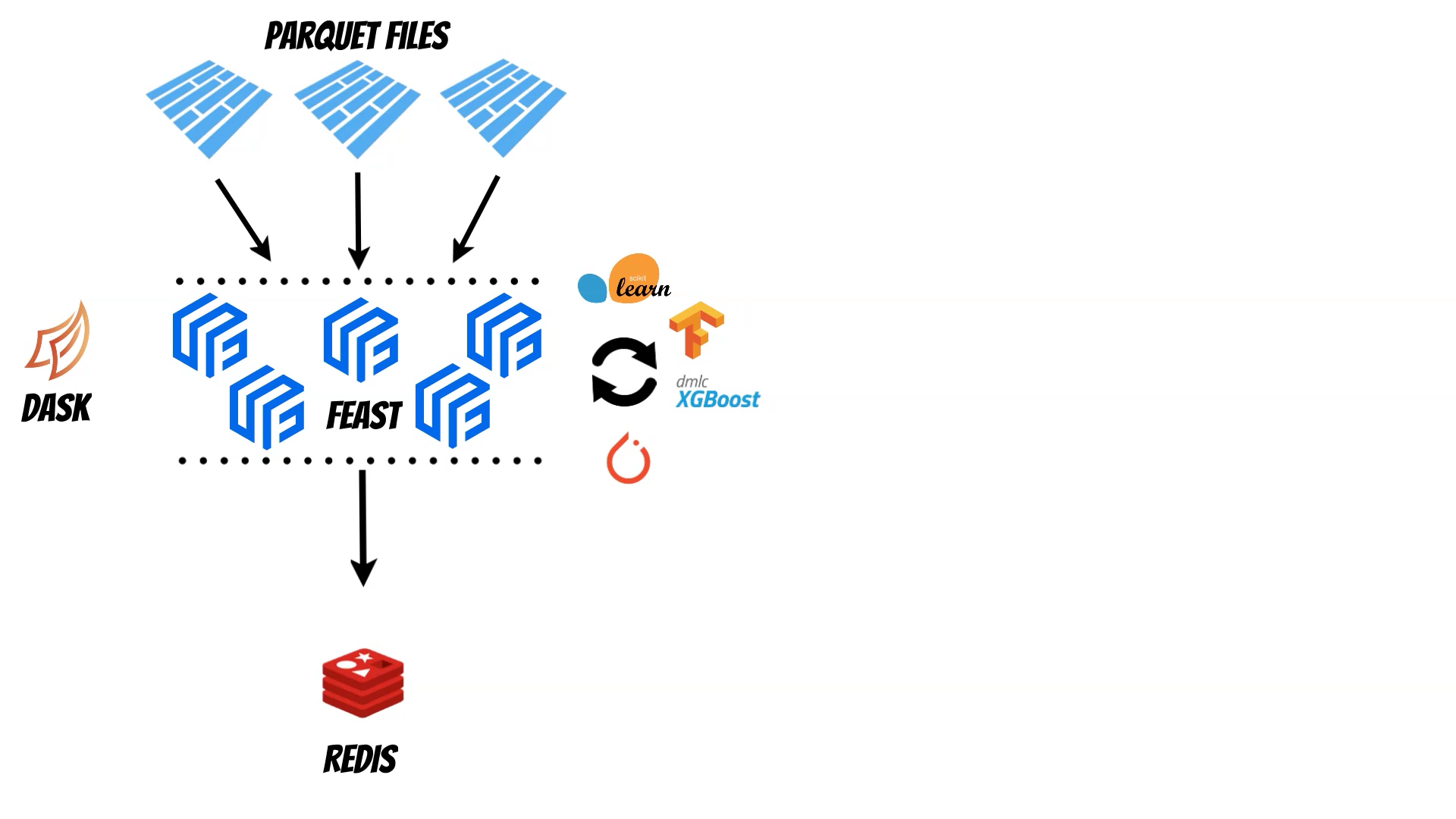
I have prepared ready to use docker image thus you can simply reproduce all steps.
docker run --name feast -d --rm -p 8888:8888 -p 8787:8787 qooba/feast:dask
Then check the Jupyter notebook token which you will need to login:
docker logs -f feast
And open (use the token to login):
http://localhost:8888/notebooks/feast-dask/feast-dask.ipynb#/slide-0-0
The notebook is also available on https://github.com/qooba/feast-dask/blob/main/docker/feast-dask.ipynb.
But with the docker you will have the whole environment ready.
In the notebook you will can find all the steps:
Random data generation
I have used numpy and scikit-learn to generate 1M entities end historical data (10 features generated with make_hastie_10_2 function) for 14 days which I save as a parquet file (1.34GB).
Feast configuration and registry
feature_store.yaml - where I use local registry and Sqlite database as a online store.
features.py - with one file source (generate parquet) and features definition.
The create the Feast registry we have to run:
feast apply
Additionally I have created simple library which helps to inspect feast schema directly in the Jupyter notebook
pip install feast-schema
from feast_schema import FeastSchema
FeastSchema('.').show_schema()
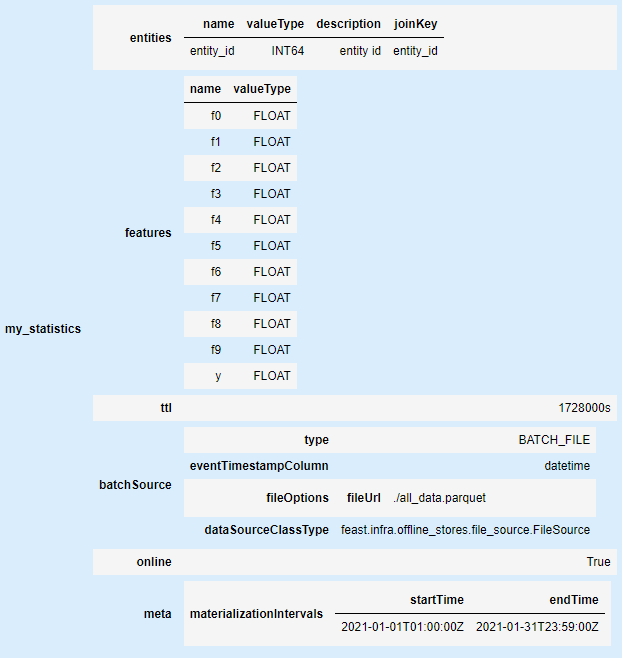
Dask cluster setup
Then I setup simple Dask cluster with scheduler and 4 workers.
dask-scheduler --host 0.0.0.0 --port 8786 --bokeh-port 8787 &
dask-worker --host 0.0.0.0 0.0.0.0:8786 --worker-port 8701 &
dask-worker --host 0.0.0.0 0.0.0.0:8786 --worker-port 8702 &
dask-worker --host 0.0.0.0 0.0.0.0:8786 --worker-port 8703 &
dask-worker --host 0.0.0.0 0.0.0.0:8786 --worker-port 8704 &
The Dask dashboard is exposed on port 8787 thus you can follow Dask metrics on:
http://localhost:8787/status
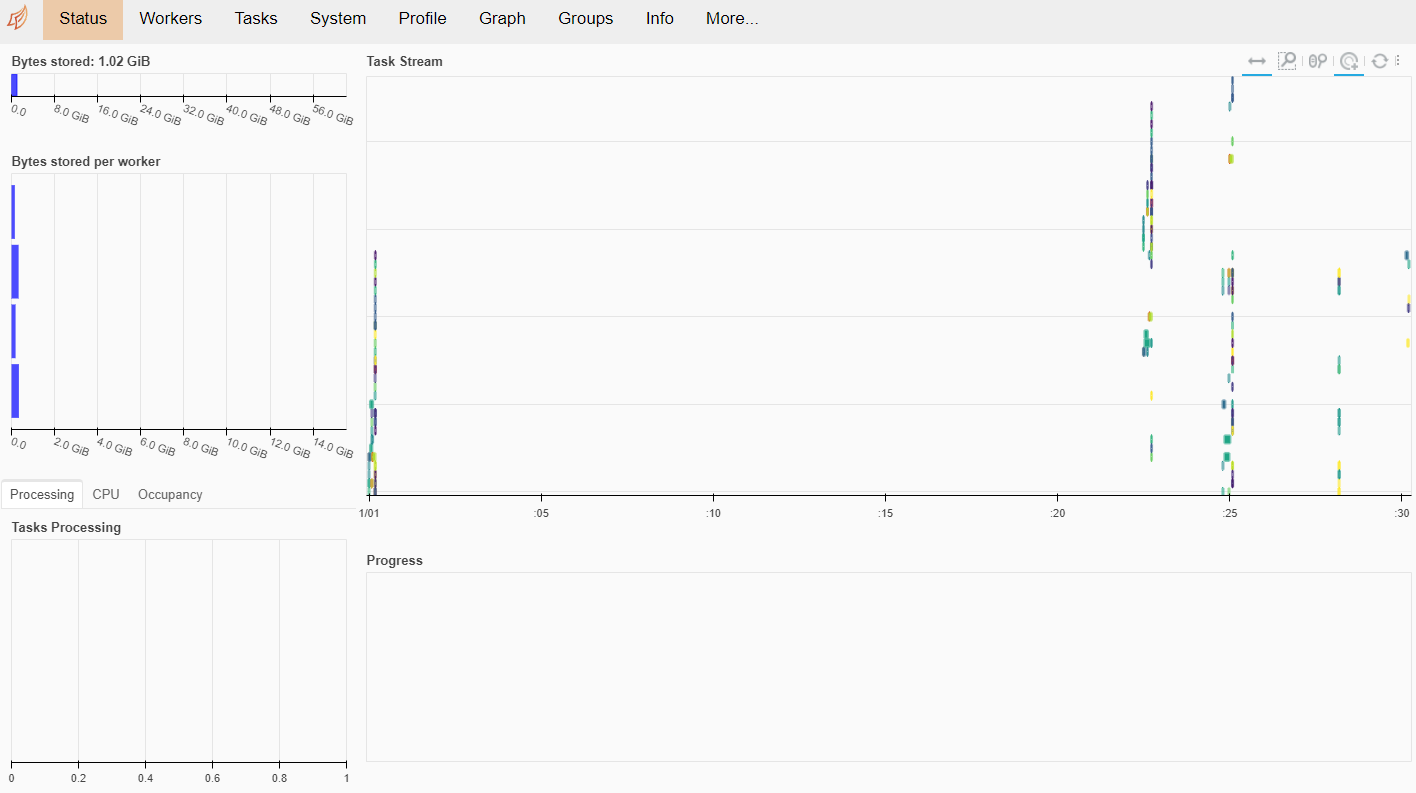
Fetching historical features
In the next step I have fetched the historical features using Feast with the Dask:
from feast import FeatureStore
store = FeatureStore(repo_path='.')
training_df = store.get_historical_features(
entity_df=entity_df,
feature_refs=[
"my_statistics:f0",
"my_statistics:f1",
"my_statistics:f2",
"my_statistics:f3",
"my_statistics:f4",
"my_statistics:f5",
"my_statistics:f6",
"my_statistics:f7",
"my_statistics:f8",
"my_statistics:f9",
"my_statistics:y",
],
).to_df()
training_df
this takes about 14 seconds and is much more faster than Feast without the Dask.
Pandas
CPU times: user 2min 51s, sys: 6.64 s, total: 2min 57s
Wall time: 2min 52s
Dask
CPU times: user 458 ms, sys: 65.3 ms, total: 524 ms
Wall time: 14.7 s
Distributed training with Sklearn
After fetching the data we can start with the training. We can used fetched Pandas dataframe but we can also fetch Dask dataframe instead:
from feast import FeatureStore
store=FeatureStore(repo_path='.')
training_dd = store.get_historical_features(
entity_df=entity_df,
feature_refs=[
"my_statistics:f0",
"my_statistics:f1",
"my_statistics:f2",
"my_statistics:f3",
"my_statistics:f4",
"my_statistics:f5",
"my_statistics:f6",
"my_statistics:f7",
"my_statistics:f8",
"my_statistics:f9",
"my_statistics:y",
]
).evaluation_function()
Using Dask dataframe we can continue distributed training with the distributed data. On the other hand if we will use Pandas dataframe the data will be computed to the one node.
To start distributed training with scikit-learn we can use Joblib library with the dask backend:
import joblib
from sklearn.ensemble import GradientBoostingClassifier
from dask_ml.model_selection import train_test_split
predictors = training_dd[["f0","f1","f2","f3","f4","f5","f6","f7","f8","f9"]]
targets = training_dd[["y"]]
X_train, X_test, y_train, y_test = train_test_split(predictors, targets, test_size=.3)
with joblib.parallel_backend('dask'):
clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0, verbose=1).fit(X_train, y_train)
score=clf.score(X_test, y_test)
score
Online features materialization
Finally I have materialized the data to the local Sqlite database:
feast materialize 2021-01-01T01:00:00 2021-01-31T23:59:00
In this case the materialization data is also prepared using Dask.