How to use large language models on CPU with Rust ?
11 Jun 2023
Currently large language models gain popularity due to their impressive capabilities. However, running these models often requires powerful GPUs, which can be a barrier for many developers. LLM a Rust library developed by the Rustformers GitHub organization is designed to run several large language models on CPU, making these powerful tools more accessible than ever.
Before you will continue reading please watch short introduction:
Currently GGML a tensor library written in C that provides a foundation for machine learning applications is used as a LLM backend.
GGML library uses a technique called model quantization. Model quantization is a process that reduces the precision of the numbers used in a machine learning model. For instance, a model might use 32-bit floating-point numbers in its calculations. Through quantization, these can be reduced to lower-precision formats, such as 16-bit integers or even 8-bit integers.
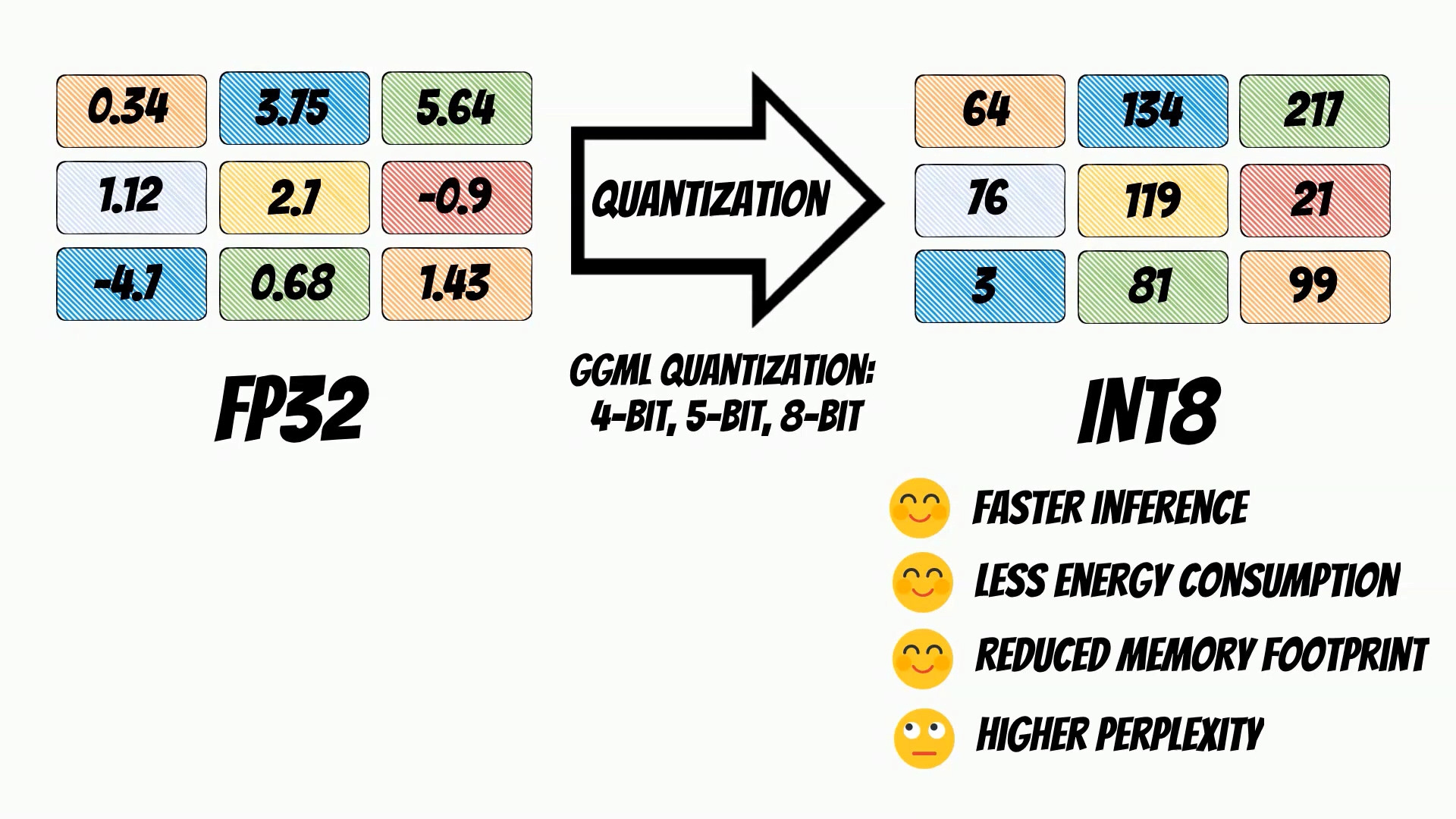
The GGML library, which Rustformers is built upon, supports a number of different quantization strategies. These include 4-bit, 5-bit, and 8-bit quantization. Each of these offers different trade-offs between efficiency and performance. For instance, 4-bit quantization will be more efficient in terms of memory and computational requirements, but it might lead to a larger decrease in model performance compared to 8-bit quantization.
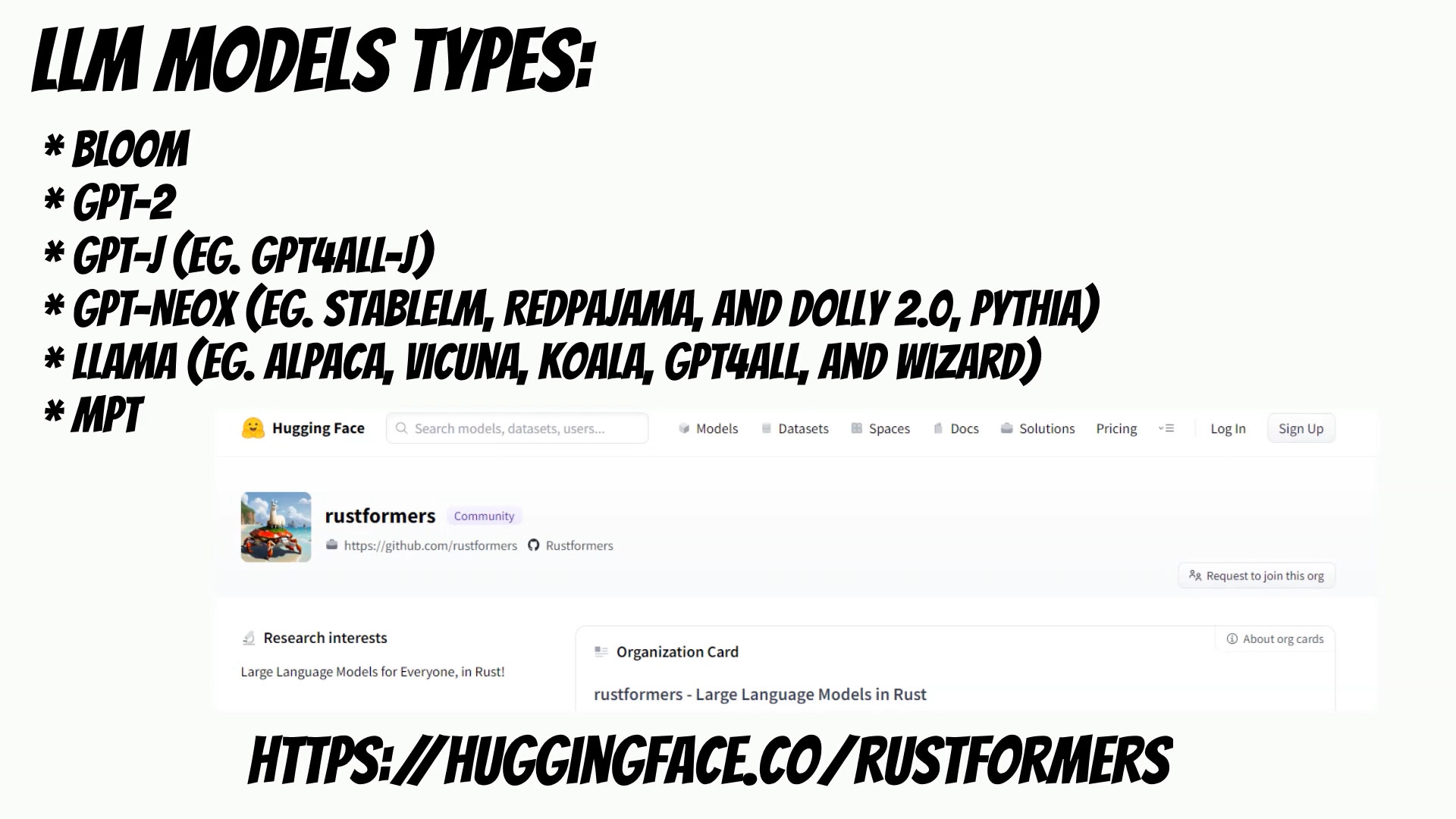
LLM supports a variety of large language models, including:
- Bloom
- GPT-2
- GPT-J
- GPT-NeoX
- Llama
- MPT
The models needs to be converted into form readable by GGML library but thanks to the authors you can find ready to use models on huggingface.
To test it you can install llm-cli packge. Then you can chat with the model in the console.
cargo install llm-cli --git https://github.com/rustformers/llm
llm gptj infer -m ./gpt4all-j-q4_0-ggjt.bin -p "Rust is a cool programming language because"
To be able to talk with the model using http I have used actix server and built Rest API. Api expose endpoint which returns response asyncronously.
The solution is acomplished with simple UI interface.
To run it you need to clone the repository.
git clone https://github.com/qooba/llm-ui.git
Download selected model from hugging face.
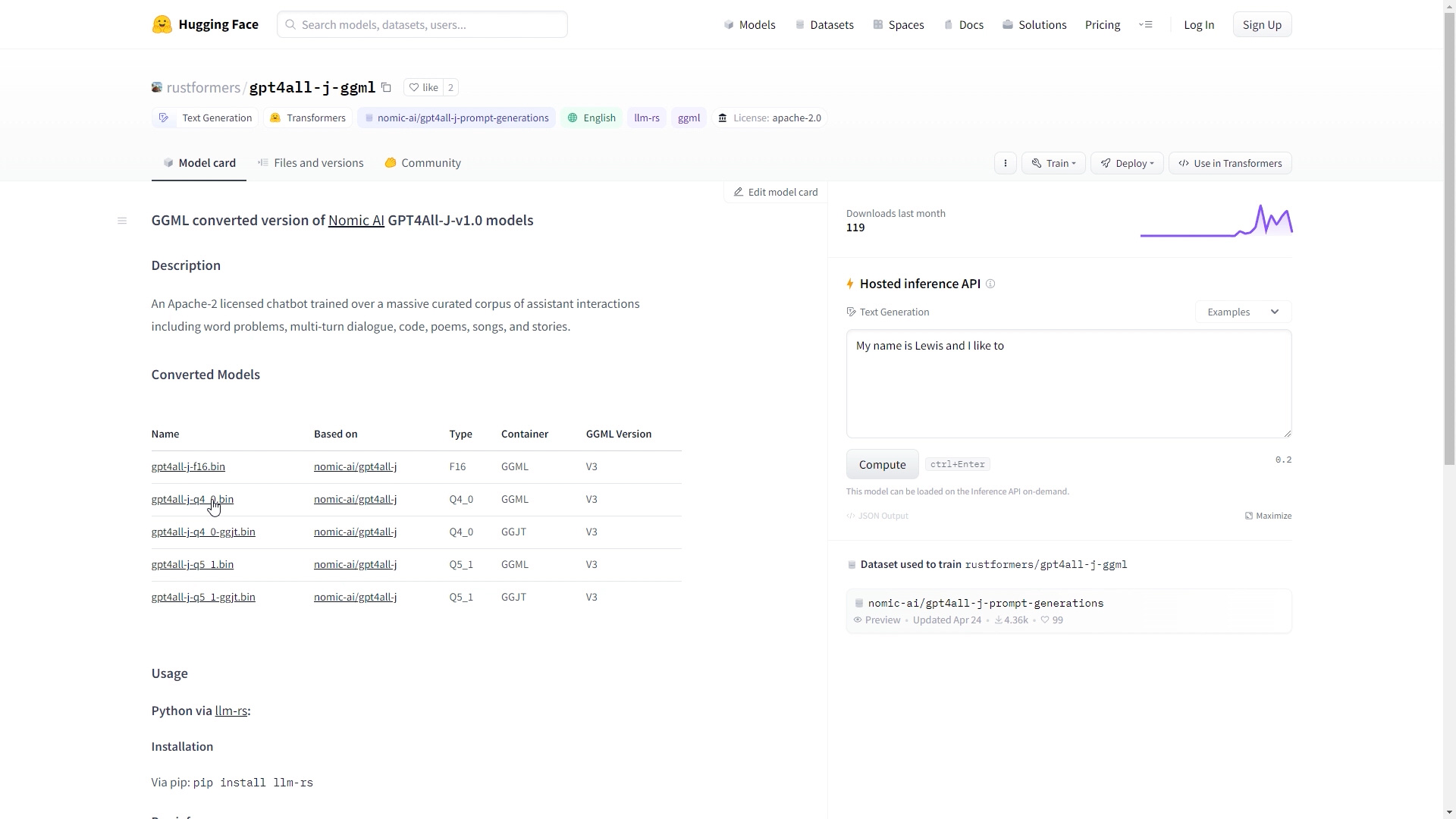
curl -LO https://huggingface.co/rustformers/gpt4all-j-ggml/resolve/main/gpt4all-j-q4_0-ggjt.bin
In our case we will use gpt4all-j model with 4-bit quantization.
Finally we use cargo run in release mode with additional arguments host, port, model type and path to the model.
cargo run --release -- --host 0.0.0.0 --port 8089 gptj ./gpt4all-j-q4_0-ggjt.bin
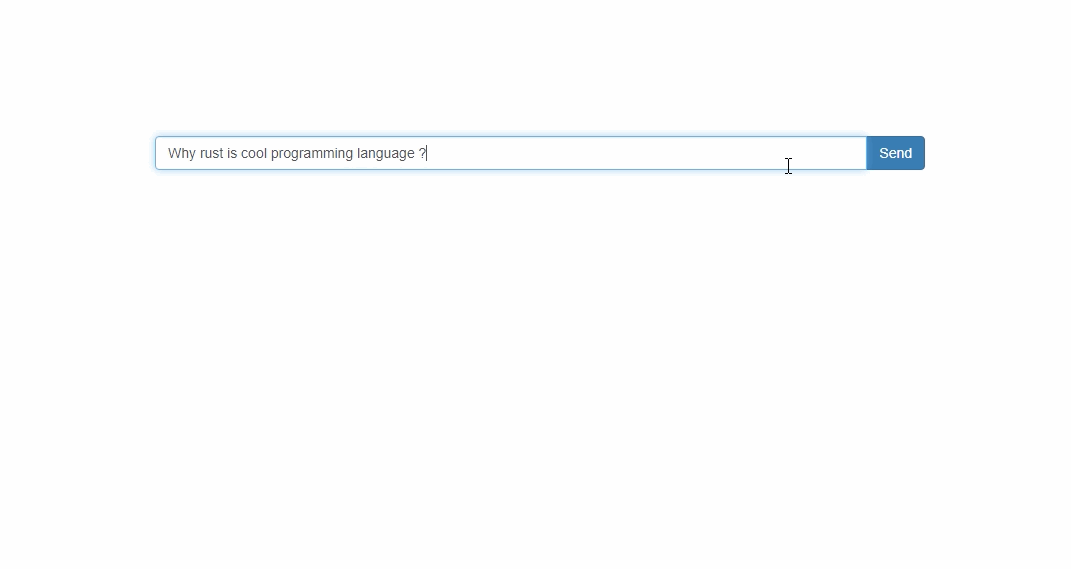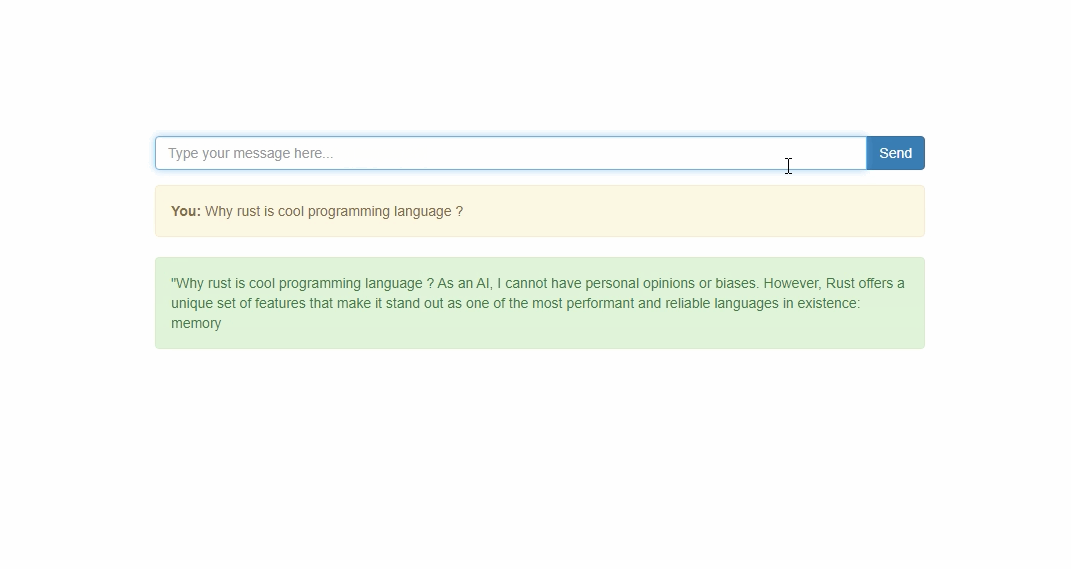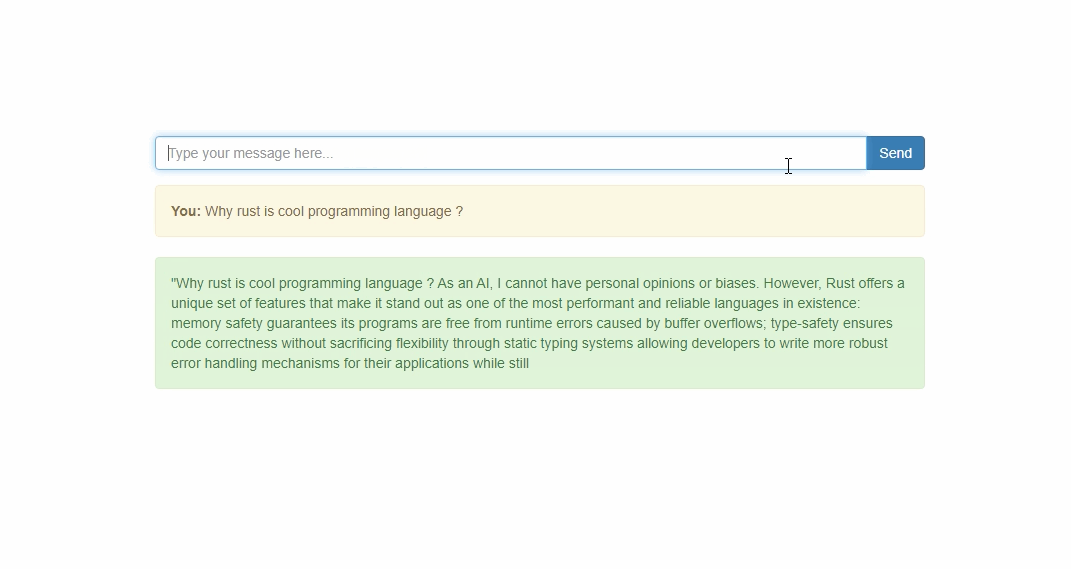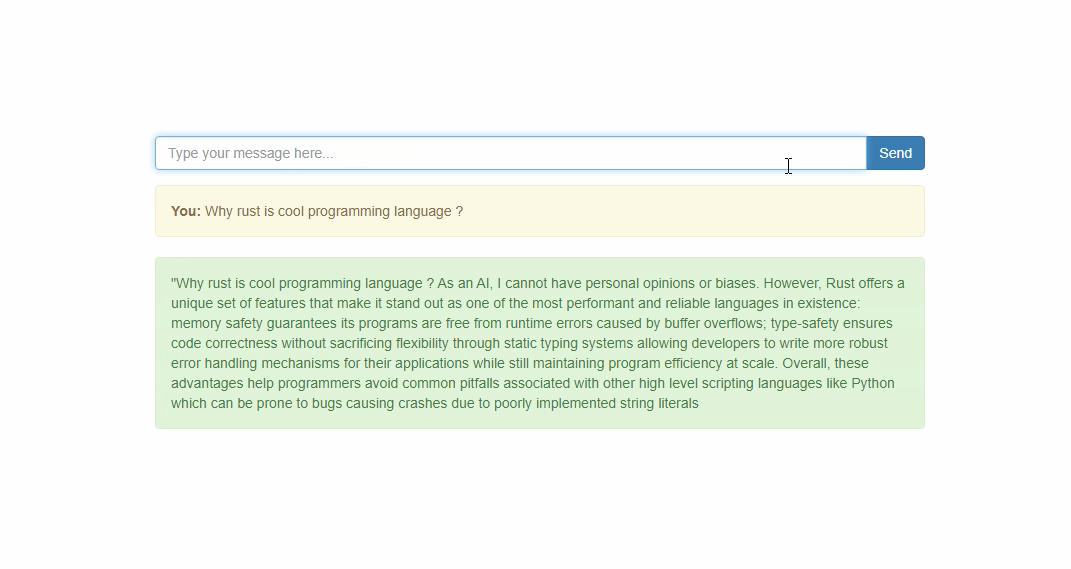
Now we are ready to call rest api or talk with the model using ui interface.