Improve the performance of MLflow models with Rust
15 Dec 2022
Realtime models deployment is a stage where performance is critical. In this article I will show how to speedup MLflow models serving and decrease resource consumption.
Additionally benchmark results will be presented.
Before you will continue reading please watch short introduction:
The Mlflow is opensource platform which covers end to end machine learning lifecycle
Including: Tracking experiments, Organizing code into reusable projects, Models versioning and finally models deployment.

With Mlflow we can easily serve versioned models.
Moreover it supports multiple ML frameworks and abstracts them with consistent Rest API.
Thanks to this we can experiment with multiple models flavors without affecting existing integration.
Mlflow is written in python and uses python to serve real-time models. This simplifies the integration with ML frameworks which expose python API.
On the other hand real-time models serving is a stage where prediction latency and resource consumption is critical.
Additionally serving robustness is required even for higher load.
To check how the rust implementation will perform I have implemented the ML models server which can read Mlflow models and expose the same Rest API.
For test purposes I have implemented integration with LightGBM and Catboost models flavors. Where I have used Rust bindings to the native libraries.
I have used Vegeta attack to perform load tests and measure p99 response time for a different number of requests per seconds. Additionally I have measured the CPU and memory usage of the model serving container. All tests have been performed on my local machine.
The performance tests show that rust implementation is very promising.
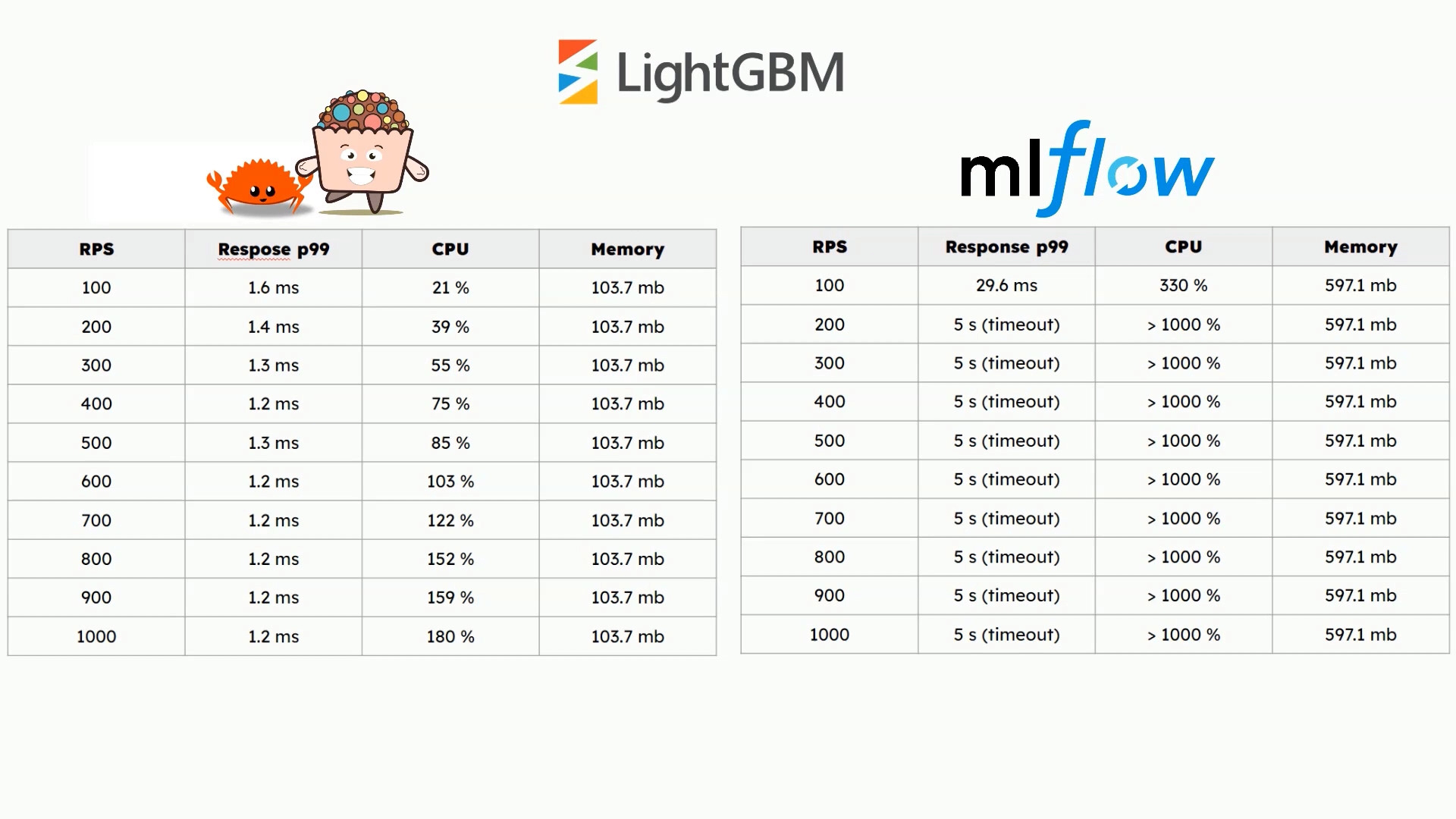
For all models even for 1000 requests per second the response time is low. CPU usage increases linearly as traffic increases. And memory usage is constant.
On the other hand Mlflow serving python implementation performs much worse and for higher traffic the response times are higher than 5 seconds which exceeds timeout value. CPU usage quickly consumes available machine resources. The memory usage is stable for all cases.
The Rust implementation is wrapped with the python api and available in yummy. Thus you can simply install and run it through the command line or using python code.
pip install yummy-mlflow
import yummy_mlflow
# yummy_mlflow.model_serve(MODEL_PATH, HOST, POST, LOG_LEVEL)
yummy_mlflow.model_serve(model_path, '0.0.0.0', 8080, 'error')
Example requests:
curl -X POST "http://localhost:8080/invocations" \
-H "Content-Type: application/json" \
-d '{
"columns": ["0","1","2","3","4","5","6","7","8","9","10",
"11","12"],
"data": [
[ 0.913333, -0.598156, -0.425909, -0.929365, 1.281985,
0.488531, 0.874184, -1.223610, 0.050988, 0.342557,
-0.164303, 0.830961, 0.997086,
]]
}'
Example response:
[[0.9849612333276241, 0.008531186707393178, 0.006507579964982725]]
The whole implementation and benchmark code is available on Github. Currently LightGBM and Catboost local models are supported.
The Yummy mlflow models server usage description is available on: https://www.yummyml.com/yummy-mlflow-models-serving