Green Screen anywhere ? … sure, video matting with AI.
26 Jun 2022
In this article I’d like to show how to predict video matte using machine learning model.
Before you will continue reading please watch short introduction:
In the previous article I have shown how to cut the background from the image: AI Scissors – sharp cut with neural networks. This time we will generate matte for video without green box using machine learning model.
Video matting, is a technique which helps to separate video into two or more layers, for example foreground and background. Using this method, we generate alpha matte, which determine the boundaries between the layers, and allows for example to substitute the background.
Nowadays these methods, are widely used in video conference software, and probably you know it very well.
But is it possible, to process 4K video and generate a high resolution alpha matte, without green screen props ? Following the article: arxiv 2108.11515 we can achieve this using: “The Robust High-Resolution Video Matting with Temporal Guidance method”.
The authors, have used recurrent architecture to exploit temporal information. Thus the model predictions, are more coherent and this improves matting robustness.

Moreover, their proposed new training strategy, where they use both matting (VideoMatte240K, Distinctions-646, Adobe Image Matting) and segmentation datasets (YouTubeVIS, COCO). This mixture helps to achieve better quality, for complex datasets and prevents overfitting.
Neural network architecture, consists of three elements.
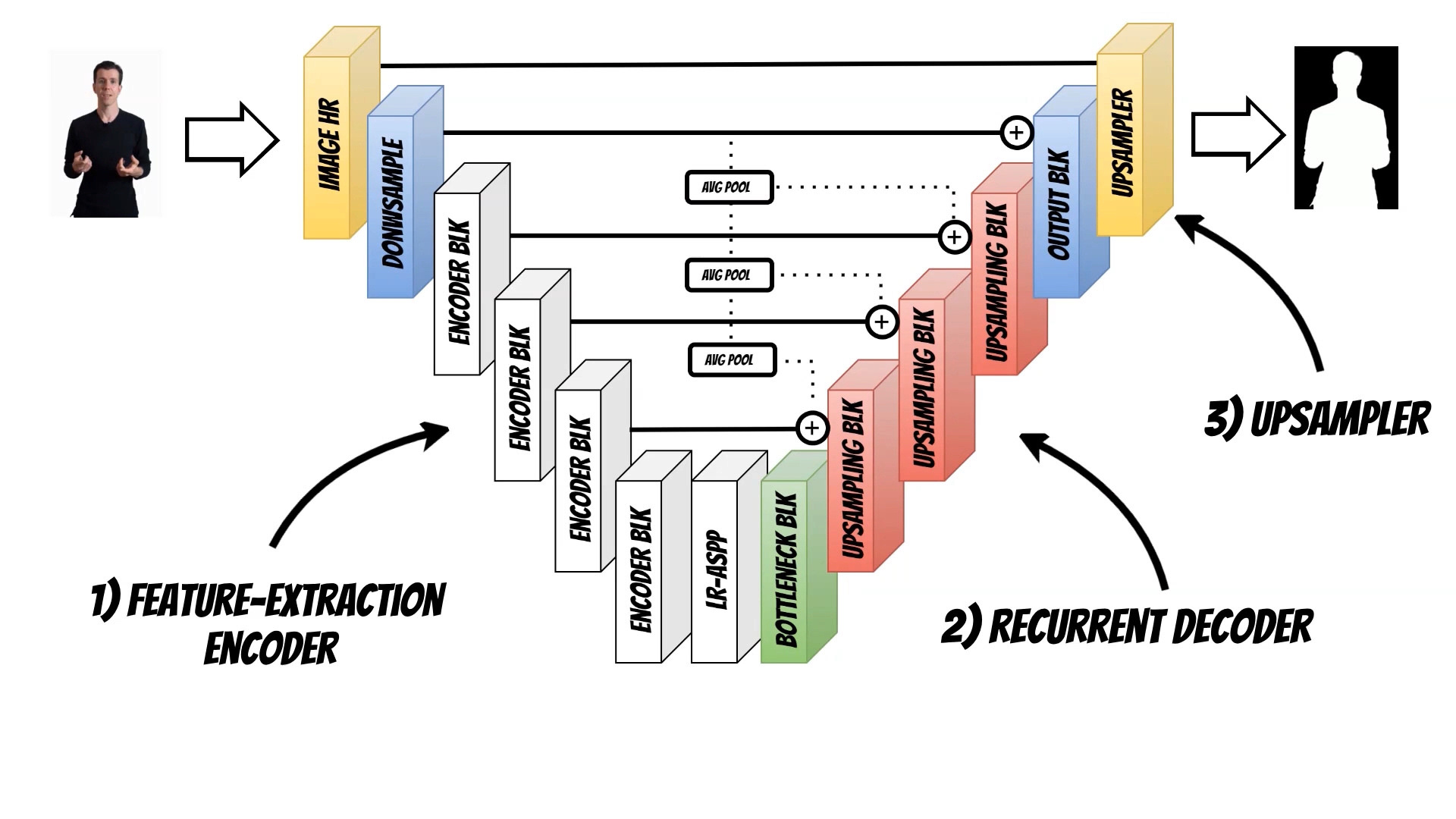
The first element is Feature-Extraction Encoder, which extracts individual frames features, especially accurately locating human subjects. The encoder, is based on the MobileNetV3-Large backbone.
The second element is Recurrent Decoder, that aggregates temporal information. Recurrent approach helps to learn, what information to keep and forget by itself, on a continuous stream of video.
And Finally Deep Guided Filter module for high-resolution upsampling.
Because the authors shared their work and models, I have prepared an easy to use docker based application which we can use to simply process your video.
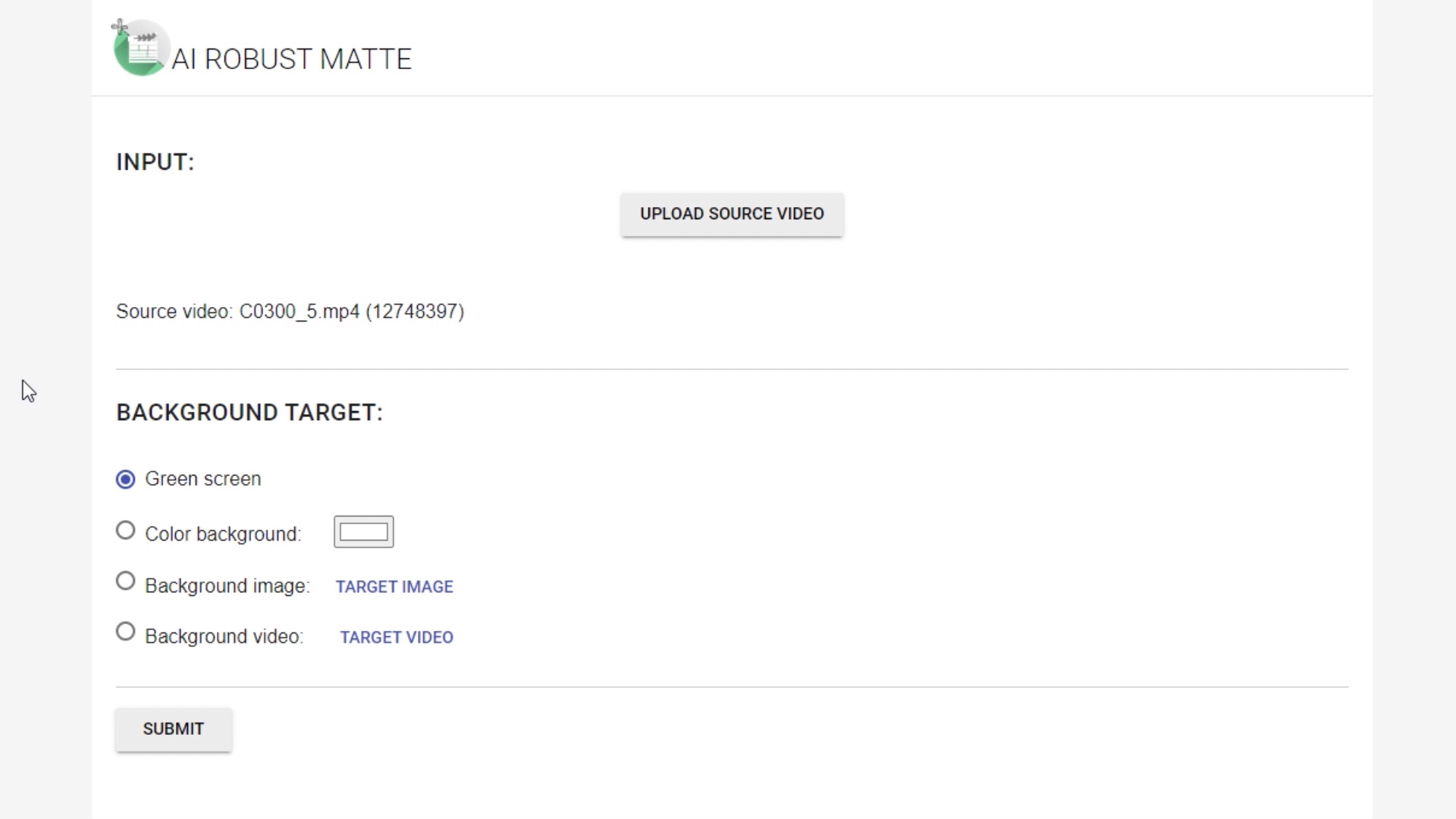
To run it you will need docker and you can run it with GPU or without GPU card.
With GPU:
docker run -it --gpus all -p 8000:8000 --rm --name aimatting qooba/aimatting:robust
Without GPU:
docker run -it -p 8000:8000 --rm --name aimatting qooba/aimatting:robust
Then open address http://localhost:8000/ in your browser.
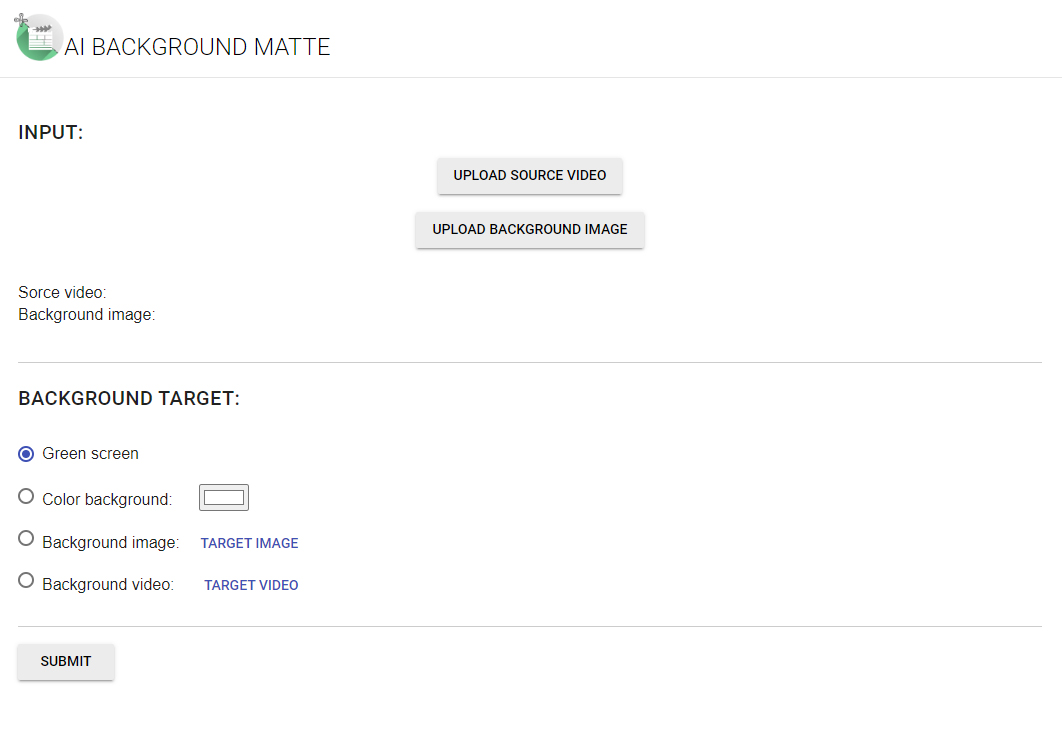
Because the model does not require any auxiliary inputs such as a trimap or a pre-captured background image we simply upload our video and choose required the background. Currently we can generate green screen background which can be then replaced in the video editing software. We can also use predefined color, image or even video.
I have also prepared the app for the older algorithm version: arxiv 2012.07810
To use please run:
docker run -it --gpus all -p 8000:8000 --rm --name aimatting qooba/aimatting:background
This version additionally requires the background image but sometimes achieves better results.