Feast with AI – feed your MLflow models with feature store
22 May 2021
In this article I will show how to prepare complete MLOPS solution based on the Feast feature store and MLflow platform.
Before you will continue reading please watch short introduction:
The whole solution will be deployed on the kubernetes (mlflow_feast.yaml).

We will use:
- Feast - as a Feature Store
- MLflow - as model repository
- Minio - as a S3 storage
- Jupyter notebook - as a workspace
- Redis - for a online features store

To better visualize the whole process we will use the Propensity to buy example where I base on the Kaggle examples and data.
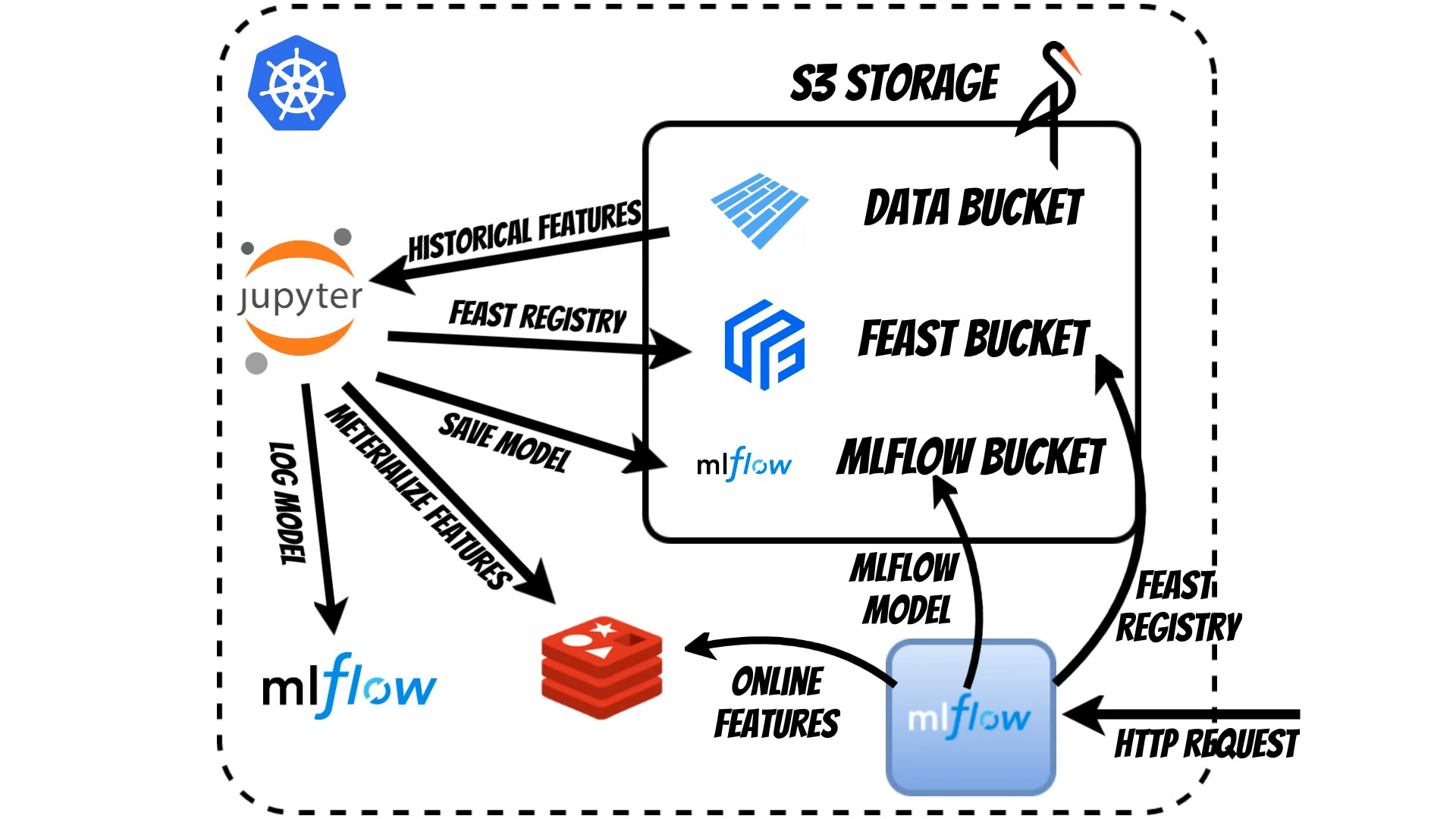
We start in Jupyter Notebook where we prepare Feast feature store schema which is kept in S3.
We can simply inspect the Feast schema in Jupyter Notebook:
from feast import FeatureStore
from IPython.core.display import display, HTML
import json
from json2html import *
import warnings
warnings.filterwarnings('ignore')
class FeastSchema:
def __init__(self, repo_path: str):
self.store = FeatureStore(repo_path=repo_path)
def show_schema(self, skip_meta: bool= False):
feast_schema=self.__project_show_schema(skip_meta)
display(HTML(json2html.convert(json = feast_schema)))
def show_table_schema(self, table: str, skip_meta: bool= False):
feasture_tables_dictionary=self.__project_show_schema(skip_meta)
display(HTML(json2html.convert(json = {table:feasture_tables_dictionary[table]})))
def __project_show_schema(self, skip_meta: bool= False):
entities_dictionary={}
feast_entities=self.store.list_entities()
for entity in feast_entities:
entity_dictionary=entity.to_dict()
entity_spec=entity_dictionary['spec']
entities_dictionary[entity_spec['name']]=entity_spec
feasture_tables_dictionary={}
feast_feature_tables=self.store.list_feature_views()
for feature_table in feast_feature_tables:
feature_table_dict=json.loads(str(feature_table))
feature_table_spec=feature_table_dict['spec']
feature_table_name=feature_table_spec['name']
feature_table_spec.pop('name',None)
if 'entities' in feature_table_spec:
feature_table_entities=[]
for entity in feature_table_spec['entities']:
feature_table_entities.append(entities_dictionary[entity])
feature_table_spec['entities']=feature_table_entities
if not skip_meta:
feature_table_spec['meta']=feature_table_dict['meta']
else:
feature_table_spec.pop('input',None)
feature_table_spec.pop('ttl',None)
feature_table_spec.pop('online',None)
feasture_tables_dictionary[feature_table_name]=feature_table_spec
return feasture_tables_dictionary
FeastSchema(".").show_schema()
#FeastSchema(".").show_schema(skip_meta=True)
#FeastSchema(".").show_table_schema('driver_hourly_stats')
#FeastSchema().show_tables()
In our case we store the data in Apache Parquet files in S3 bucket. Using the Feast we can fetch the historical features and train the model using Scikit-learn library
bucket_name="propensity"
filename="training_sample"
store = FeatureStore(repo_path=".")
s3 = fs.S3FileSystem(endpoint_override=os.environ.get("FEAST_S3_ENDPOINT_URL"))
entity_df=pd.read_parquet(f'{bucket_name}/{filename}_entities.parquet', filesystem=s3)
entity_df["event_timestamp"]=datetime.now()
training_df = store.get_historical_features(
entity_df=entity_df,
feature_refs = [
'propensity_data:basket_icon_click',
'propensity_data:basket_add_list',
'propensity_data:basket_add_detail',
'propensity_data:sort_by',
'propensity_data:image_picker',
'propensity_data:account_page_click',
'propensity_data:promo_banner_click',
'propensity_data:detail_wishlist_add',
'propensity_data:list_size_dropdown',
'propensity_data:closed_minibasket_click',
'propensity_data:checked_delivery_detail',
'propensity_data:checked_returns_detail',
'propensity_data:sign_in',
'propensity_data:saw_checkout',
'propensity_data:saw_sizecharts',
'propensity_data:saw_delivery',
'propensity_data:saw_account_upgrade',
'propensity_data:saw_homepage',
'propensity_data:device_mobile',
'propensity_data:device_computer',
'propensity_data:device_tablet',
'propensity_data:returning_user',
'propensity_data:loc_uk',
'propensity_data:ordered'
],
).to_df()
predictors = training_df.drop(['propensity_data__ordered','UserID','event_timestamp'], axis=1)
targets = training_df['propensity_data__ordered']
X_train, X_test, y_train, y_test = train_test_split(predictors, targets, test_size=.3)
classifier=GaussianNB(var_smoothing=input_params['var_smoothing'])
classifier=classifier.fit(X_train,y_train)
predictions=classifier.predict(X_test)
conf_matrix=sklearn.metrics.confusion_matrix(y_test,predictions)
ac_score=sklearn.metrics.accuracy_score(y_test, predictions)
propensity_model_path = 'propensity.joblib'
joblib.dump(classifier, propensity_model_path)
artifacts = {
"propensity_model": propensity_model_path,
"feature_store": "feature_store.yaml"
}
The model will use online Feast redis features as well as additional features from the request thus we need to wrap the MLflow model and define it:
import mlflow.pyfunc
class PropensityWrapper(mlflow.pyfunc.PythonModel):
def load_context(self, context):
import joblib
from feast import FeatureStore
import pandas as pd
import os
self.model = joblib.load(context.artifacts["propensity_model"])
self.store = FeatureStore(repo_path=os.environ.get("FEAST_REPO_PATH"))
def predict(self, context, model_input):
users=list(model_input.to_dict()["UserID"].values())
feature_vector = self.store.get_online_features(
feature_refs=[
'propensity_data:basket_icon_click',
'propensity_data:basket_add_list',
'propensity_data:basket_add_detail',
'propensity_data:sort_by',
'propensity_data:image_picker',
'propensity_data:account_page_click',
'propensity_data:promo_banner_click',
'propensity_data:detail_wishlist_add',
'propensity_data:list_size_dropdown',
'propensity_data:closed_minibasket_click',
'propensity_data:checked_delivery_detail',
'propensity_data:checked_returns_detail',
'propensity_data:sign_in',
'propensity_data:saw_checkout',
'propensity_data:saw_sizecharts',
'propensity_data:saw_delivery',
'propensity_data:saw_account_upgrade',
'propensity_data:saw_homepage',
'propensity_data:returning_user',
'propensity_data:loc_uk'
],
entity_rows=[{"UserID": uid} for uid in users]
).to_dict()
data=pd.DataFrame.from_dict(feature_vector)
merged_data = pd.merge(model_input,data, how="inner", on=["UserID"], suffixes=('_x', '')).drop(['UserID'], axis=1)
return self.model.predict(merged_data)
Now we can log the MLflow model to the repository:
import warnings
import sys
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
from urllib.parse import urlparse
import mlflow
import mlflow.sklearn
import mlflow.pyfunc
#conda_env=mlflow.pyfunc.get_default_conda_env()
with mlflow.start_run():
#mlflow.log_param("var_smoothing", input_params['var_smoothing'])
mlflow.log_metric("accuracy_score", ac_score)
tracking_url_type_store = urlparse(mlflow.get_tracking_uri()).scheme
if tracking_url_type_store != "file":
mlflow.pyfunc.log_model("model",
registered_model_name="propensity_model",
python_model=PropensityWrapper(),
artifacts=artifacts,
conda_env=conda_env)
else:
mlflow.pyfunc.log_model("model",
path=my_model_path,
python_model=PropensityWrapper(),
artifacts=artifacts,
conda_env=conda_env)
We can export the code and run is using MLflow cli:
mlflow run . --no-conda --experiment-name="propensity" -P var_smoothing=1e-9
Now we need to materialize features to Redis:
feast materialize 2021-03-22T23:42:00 2021-06-22T23:42:00
Using MLflow we can simply deploy model as a microservice in k8s.
In our case we want to deploy the model models:/propensity_model/Production
which is currently assigned for Production. During start the MLflow will automatically fetch the proper model from S3:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mlflow-serving
namespace: qooba
spec:
replicas: 1
selector:
matchLabels:
app: mlflow-serving
version: v1
template:
metadata:
labels:
app: mlflow-serving
version: v1
spec:
containers:
- image: qooba/mlflow:serving
imagePullPolicy: IfNotPresent
name: mlflow-serving
env:
- name: MLFLOW_TRACKING_URI
value: http://mlflow.qooba.svc.cluster.local:5000
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: minio-auth
key: username
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: minio-auth
key: password
- name: MLFLOW_S3_ENDPOINT_URL
value: http://minio.qooba.svc.cluster.local:9000
- name: FEAST_S3_ENDPOINT_URL
value: http://minio.qooba.svc.cluster.local:9000
- name: REDIS_TYPE
value: REDIS
- name: REDIS_CONNECTION_STRING
value: redis.qooba.svc.cluster.local:6379,db=0
- name: FEAST_TELEMETRY
value: "false"
- name: FEAST_REPO_PATH
value: /feast_repository
- name: PORT
value: "5000"
- name: MODEL
value: models:/propensity_model/Production
ports:
- containerPort: 5000
volumeMounts:
- mountPath: /feast_repository
name: config
volumes:
- name: config
configMap:
name: mlflow-serving
items:
- key: feature_store
path: feature_store.yaml
On each HTTP request:
import requests
import json
url="http://mlflow-serving.qooba.svc.cluster.local:5000/invocations"
headers={
'Content-Type': 'application/json; format=pandas-records'
}
data=[
{"UserID": "a720-6b732349-a720-4862-bd21-644732",
'propensity_data:device_mobile': 1.0,
'propensity_data:device_computer': 0.0,
'propensity_data:device_tablet': 0.0
}
]
response=requests.post(url, data=json.dumps(data), headers=headers)
response.text
The model will fetch the client features (based on UserID) from Redis and HTTP request and generate prediction.