In this article I will show how to improve the quality of blurred face images using
artificial intelligence. For this purpose I will use neural networks and FastAI library (ver. 1)
Before you will continue reading please watch short introduction:
I have based o lot on the fastai course thus I definitely recommend to go through it.
Data
To train neural network how to rebuild the face images we need to provide the
faces dataset which will show how low quality and blurred images should be reconstructed.
Thus we need pairs of low and high quality images.
We will treat the original images as a high resolution data and rescale them
to prepare low resolution input:
import fastai
from fastai.vision import *
from fastai.callbacks import *
from fastai.utils.mem import *
from torchvision.models import vgg16_bn
from pathlib import Path
path = Path('/opt/notebooks/faces')
path_hr = path/'high_resolution'
path_lr = path/'small-96'
il = ImageList.from_folder(path_hr)
def resize_one(fn, i, path, size):
dest = path/fn.relative_to(path_hr)
dest.parent.mkdir(parents=True, exist_ok=True)
img = PIL.Image.open(fn)
targ_sz = resize_to(img, size, use_min=True)
img = img.resize(targ_sz, resample=PIL.Image.BILINEAR).convert('RGB')
img.save(dest, quality=60)
sets = [(path_lr, 96)]
for p,size in sets:
if not p.exists():
print(f"resizing to {size} into {p}")
parallel(partial(resize_one, path=p, size=size), il.items)
Now we can create data bunch for training:
bs,size=32,128
arch = models.resnet34
src = ImageImageList.from_folder(path_lr).split_by_rand_pct(0.1, seed=42)
def get_data(bs,size):
data = (src.label_from_func(lambda x: path_hr/x.name)
.transform(get_transforms(max_zoom=2.), size=size, tfm_y=True)
.databunch(bs=bs,num_workers=0).normalize(imagenet_stats, do_y=True))
data.c = 3
return data
data = get_data(bs,size)
Training
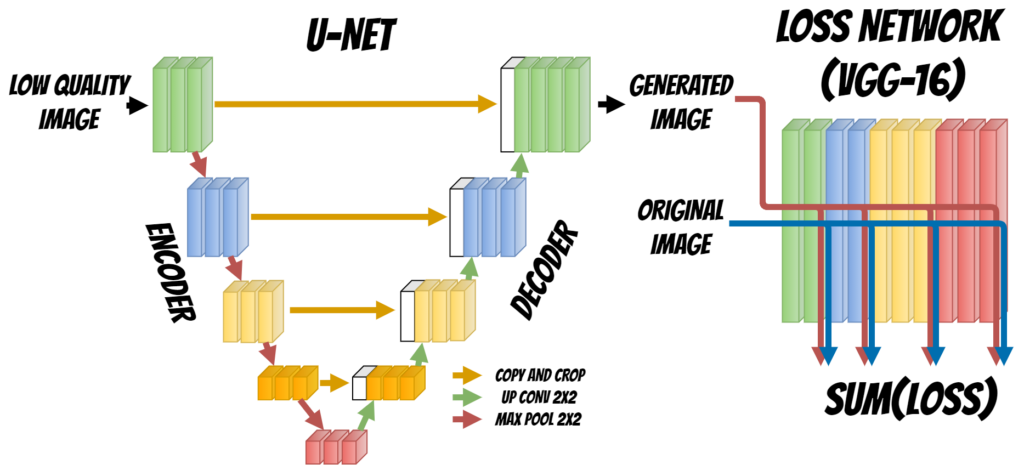
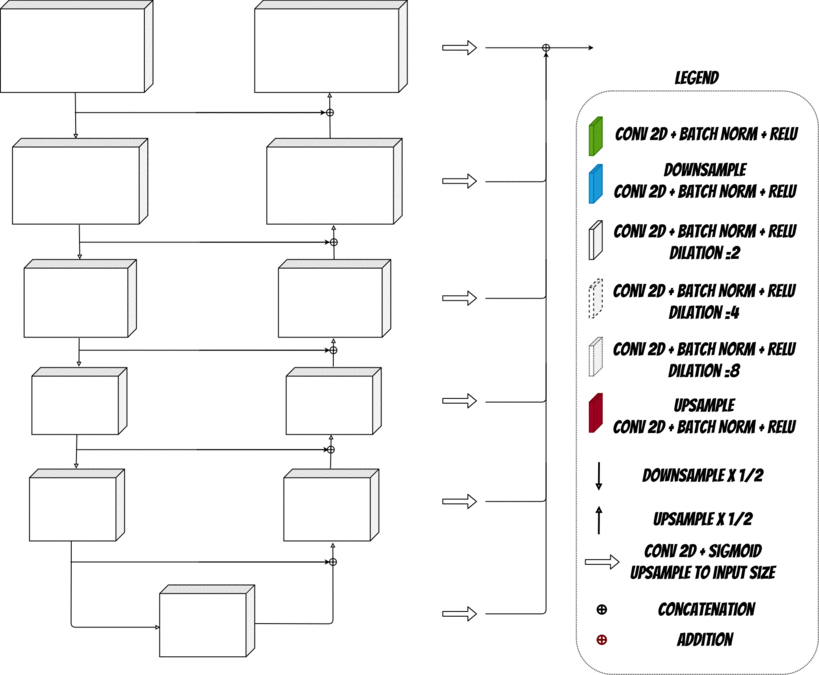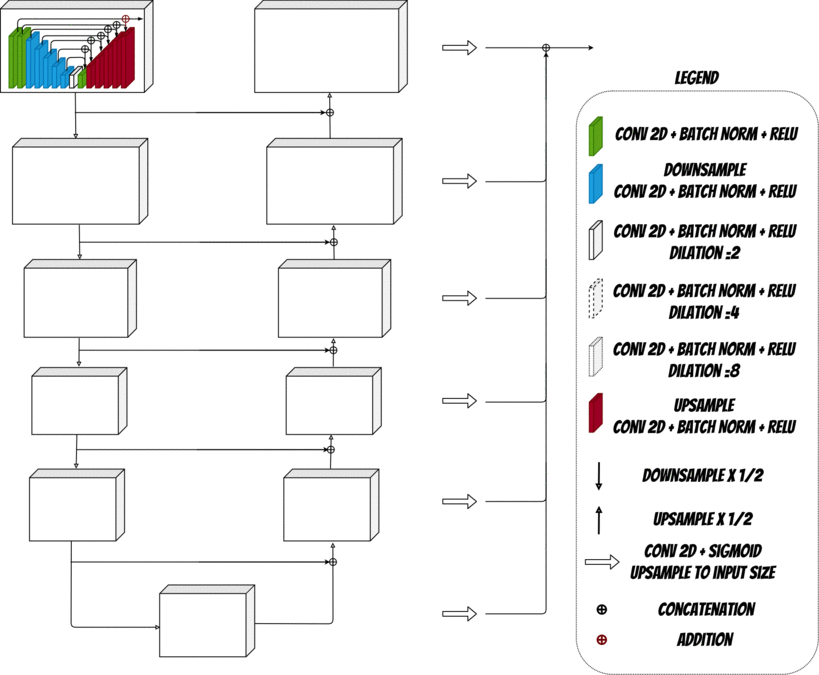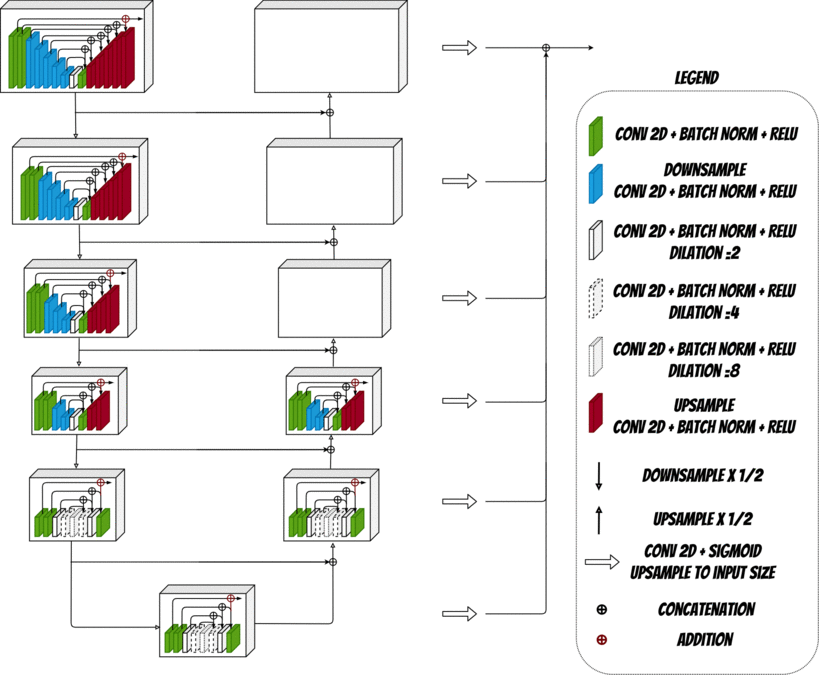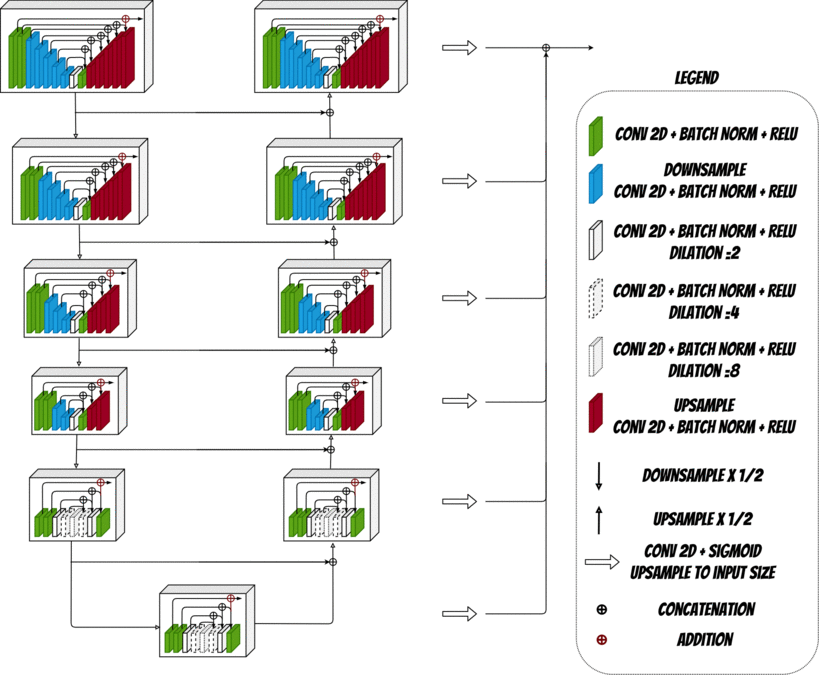
In this solution we will use a neural network with UNET architecture.
The UNET neural network contains two parts Encoder and Decoder which are used to reconstruct the face image.
During the first stage Encoder fetch the input, extracts and aggregates the image features. At each stage the features maps are donwsampled.
Then Decoder uses extracted features and tries to rebuild the image upsampling it at each decoding stage. Finally we get regenerated images.
Additionally we need to define the Loss Function which will tell the model if the image was rebuilt correctly and allow to train the model.
To do this we will use additional neural network VGG-16. We will put Generated image and Original image (which is our target) to the network input. Then will compare the features extracted for both images at selected layers and according to this calculated the loss.
Finally we will use Adam optmizer to minimize the loss and achieve better result.
def gram_matrix(x):
n,c,h,w = x.size()
x = x.view(n, c, -1)
return (x @ x.transpose(1,2))/(c*h*w)
base_loss = F.l1_loss
vgg_m = vgg16_bn(True).features.cuda().eval()
requires_grad(vgg_m, False)
blocks = [i-1 for i,o in enumerate(children(vgg_m)) if isinstance(o,nn.MaxPool2d)]
class FeatureLoss(nn.Module):
def __init__(self, m_feat, layer_ids, layer_wgts):
super().__init__()
self.m_feat = m_feat
self.loss_features = [self.m_feat[i] for i in layer_ids]
self.hooks = hook_outputs(self.loss_features, detach=False)
self.wgts = layer_wgts
self.metric_names = ['pixel',] + [f'feat_{i}' for i in range(len(layer_ids))
] + [f'gram_{i}' for i in range(len(layer_ids))]
def make_features(self, x, clone=False):
self.m_feat(x)
return [(o.clone() if clone else o) for o in self.hooks.stored]
def forward(self, input, target):
out_feat = self.make_features(target, clone=True)
in_feat = self.make_features(input)
self.feat_losses = [base_loss(input,target)]
self.feat_losses += [base_loss(f_in, f_out)*w
for f_in, f_out, w in zip(in_feat, out_feat, self.wgts)]
self.feat_losses += [base_loss(gram_matrix(f_in), gram_matrix(f_out))*w**2 * 5e3
for f_in, f_out, w in zip(in_feat, out_feat, self.wgts)]
self.metrics = dict(zip(self.metric_names, self.feat_losses))
return sum(self.feat_losses)
def __del__(self): self.hooks.remove()
feat_loss = FeatureLoss(vgg_m, blocks[2:5], [5,15,2])
learn = unet_learner(data, arch, wd=wd, loss_func=feat_loss, callback_fns=LossMetrics,
blur=True, norm_type=NormType.Weight)
Results
After training we can use the model to regenerate the images:
Application
Finally we can export the model and create the drag and drop application which fix the face images in web application.
The whole solution is packed into docker images thus you can simply start it using commands:
# with GPU
docker run -d --gpus all --rm -p 8000:8000 --name aiunblur qooba/aiunblur
# without GPU
docker run -d --rm -p 8000:8000 --name aiunblur qooba/aiunblur
To use GPU additional nvidia drivers (included in the NVIDIA CUDA Toolkit) are needed.
The popularity of drones and the area of their application is becoming greater each year.
In this article I will show how to programmatically control Tello Ryze drone, capture camera video and detect objects using Tensorflow. I have packed the whole solution into docker images (the backend and Web App UI are in separate images) thus you can simply run it.
Before you will continue reading please watch short introduction:
https://youtu.be/g8oZ8ltRArY
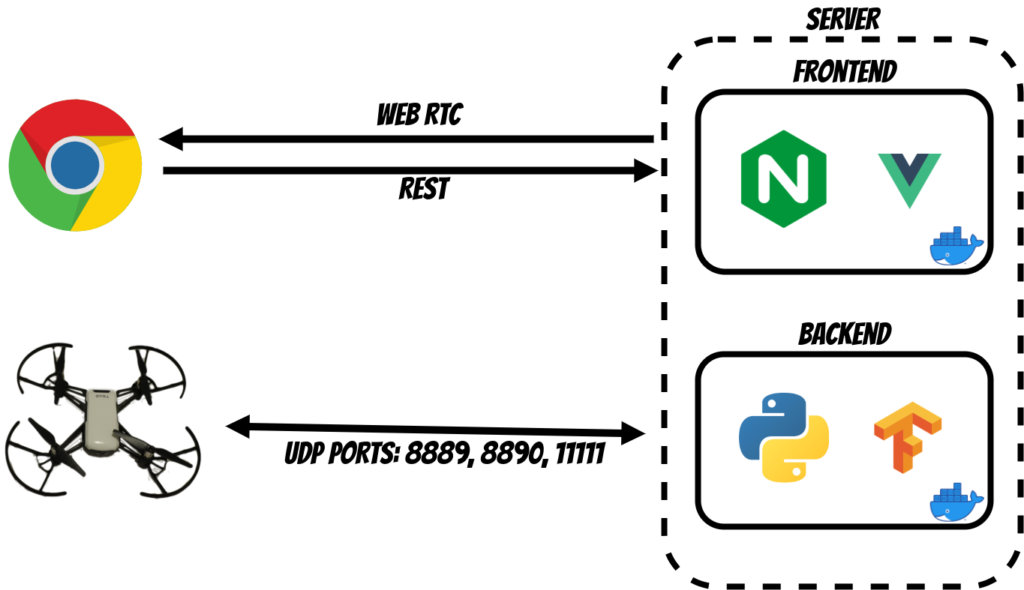
Architecture
The application will use two network interfaces.
The first will be used by the python backend to connect the the Tello wifi to send the commands and capture video stream. In the backend layer I have used the DJITelloPy library which covers all required tello move commands and video stream capture.
To efficiently show the video stream in the browser I have used the WebRTC protocol and aiortc library. Finally I have used the Tensorflow 2.0 object detection with pretrained SSD ResNet50 model.
The second network interface will be used to expose the Web Vue application.
I have used nginx to serve the frontend application
Application
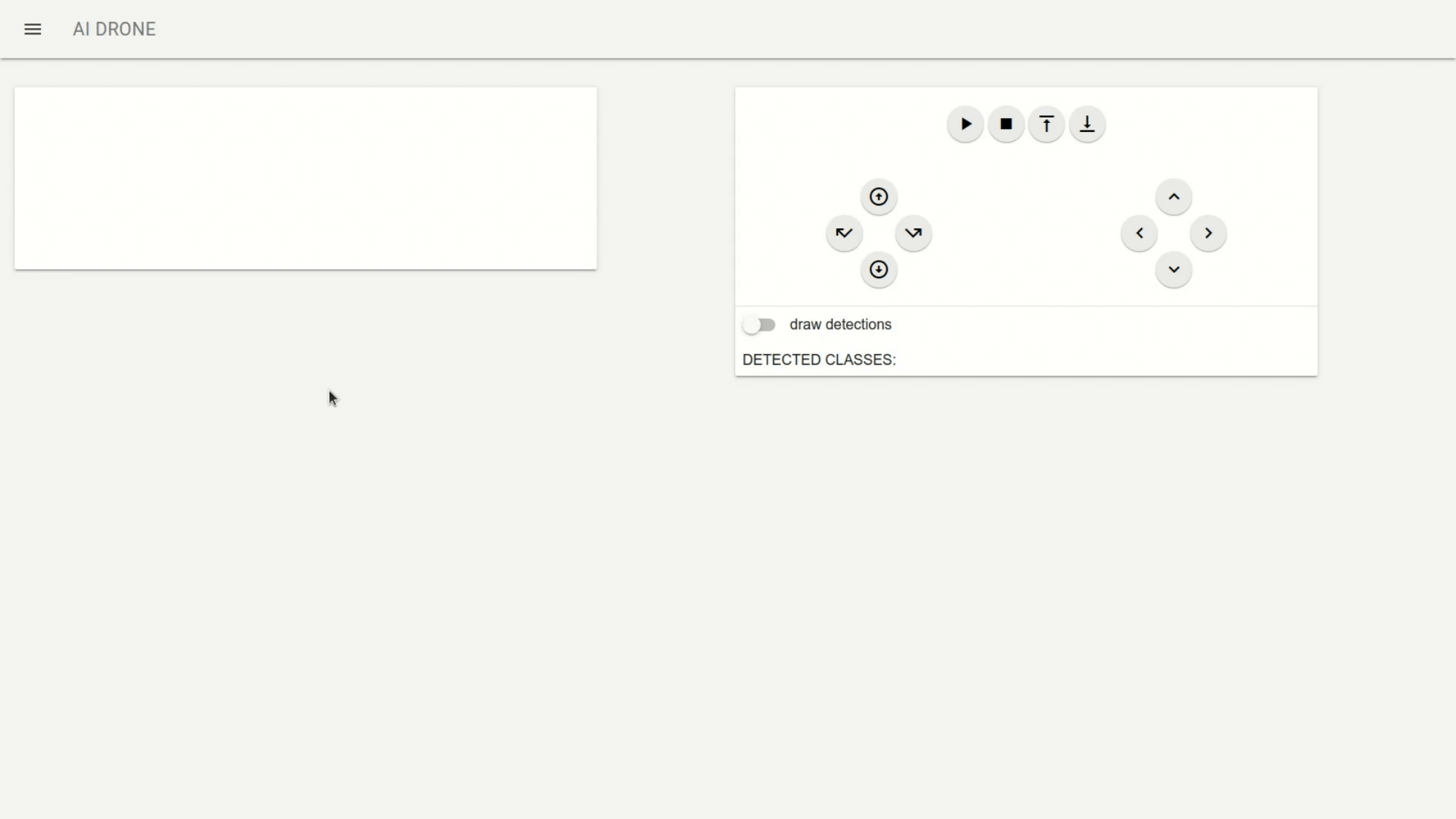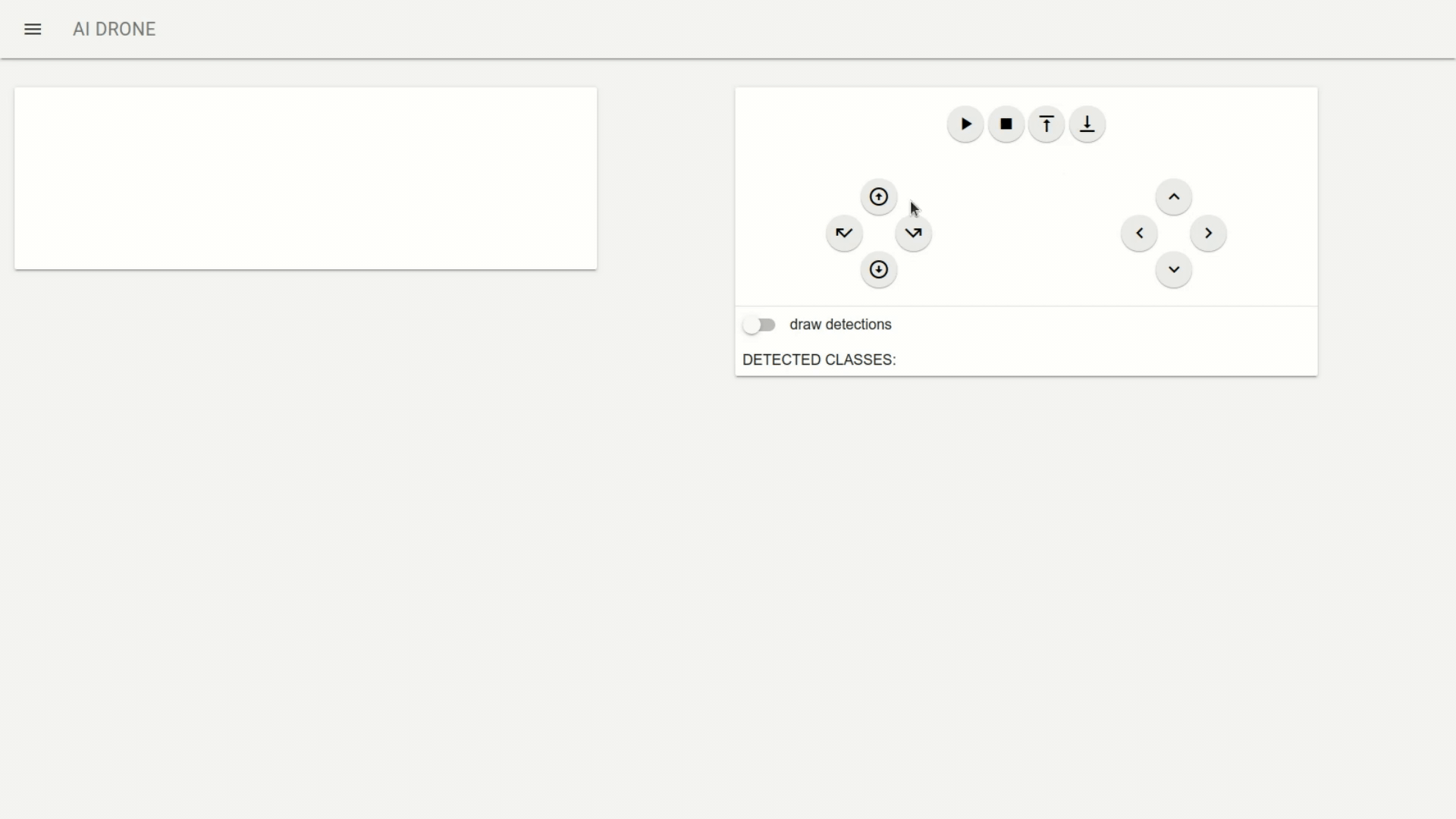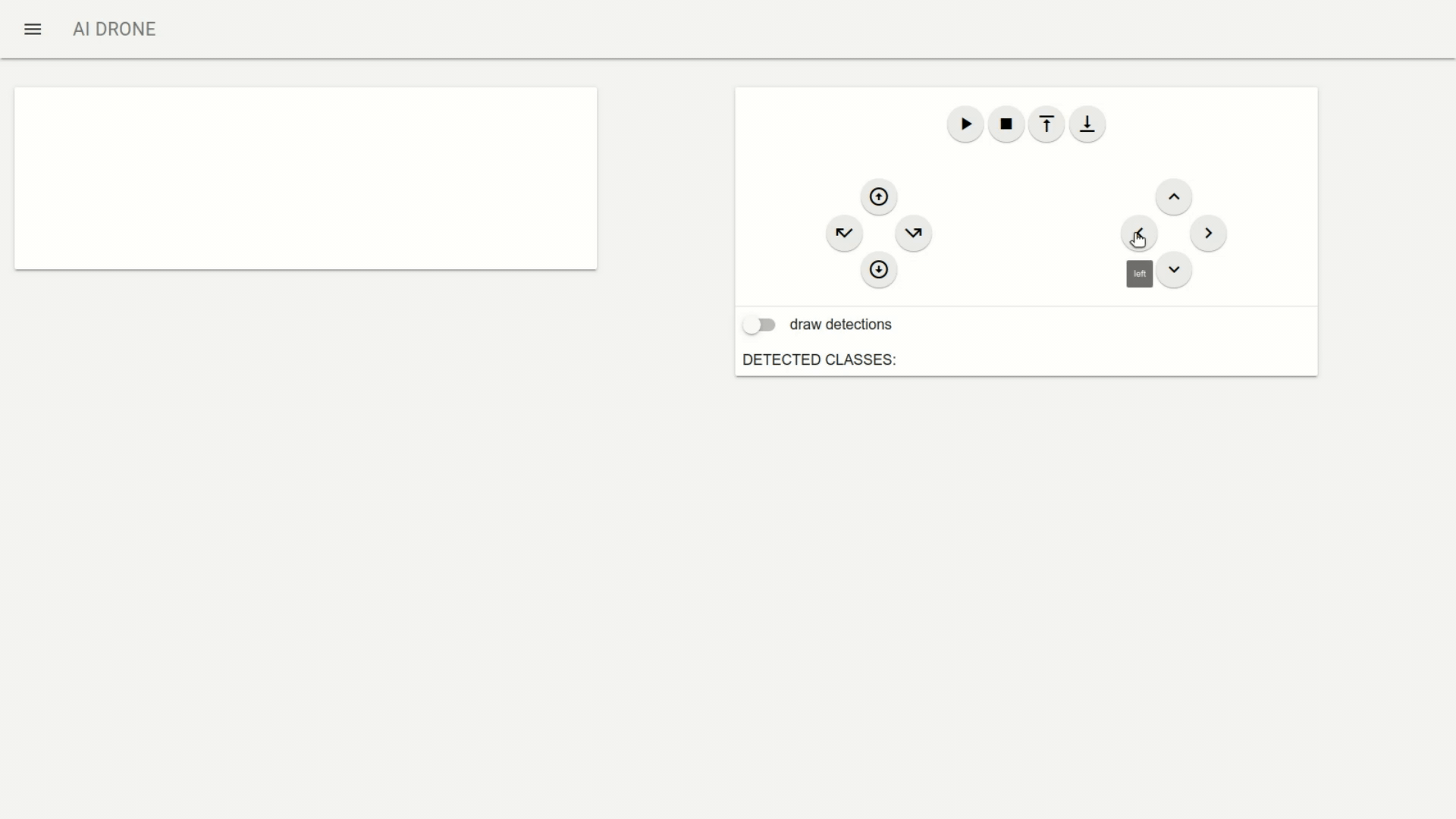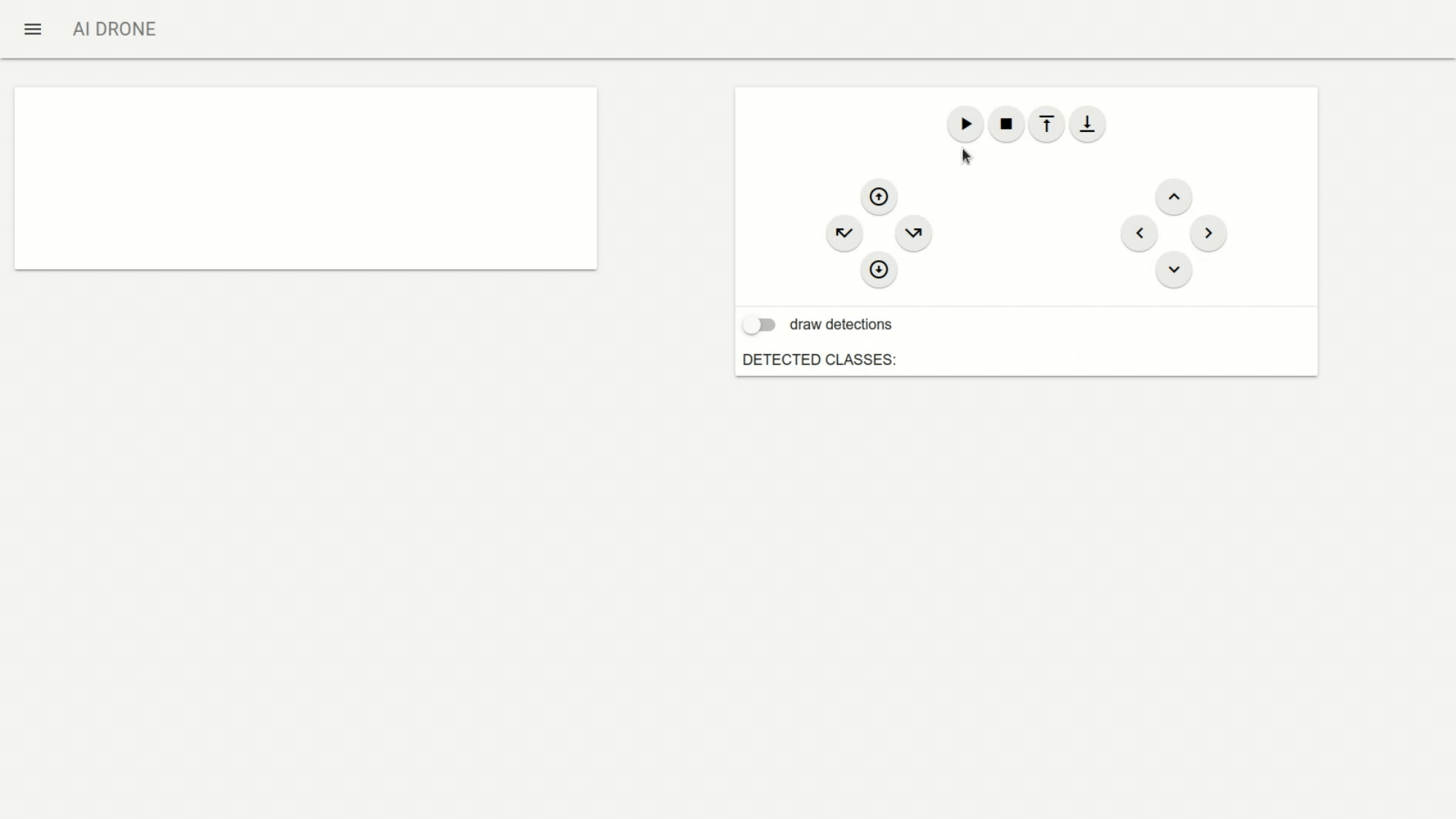
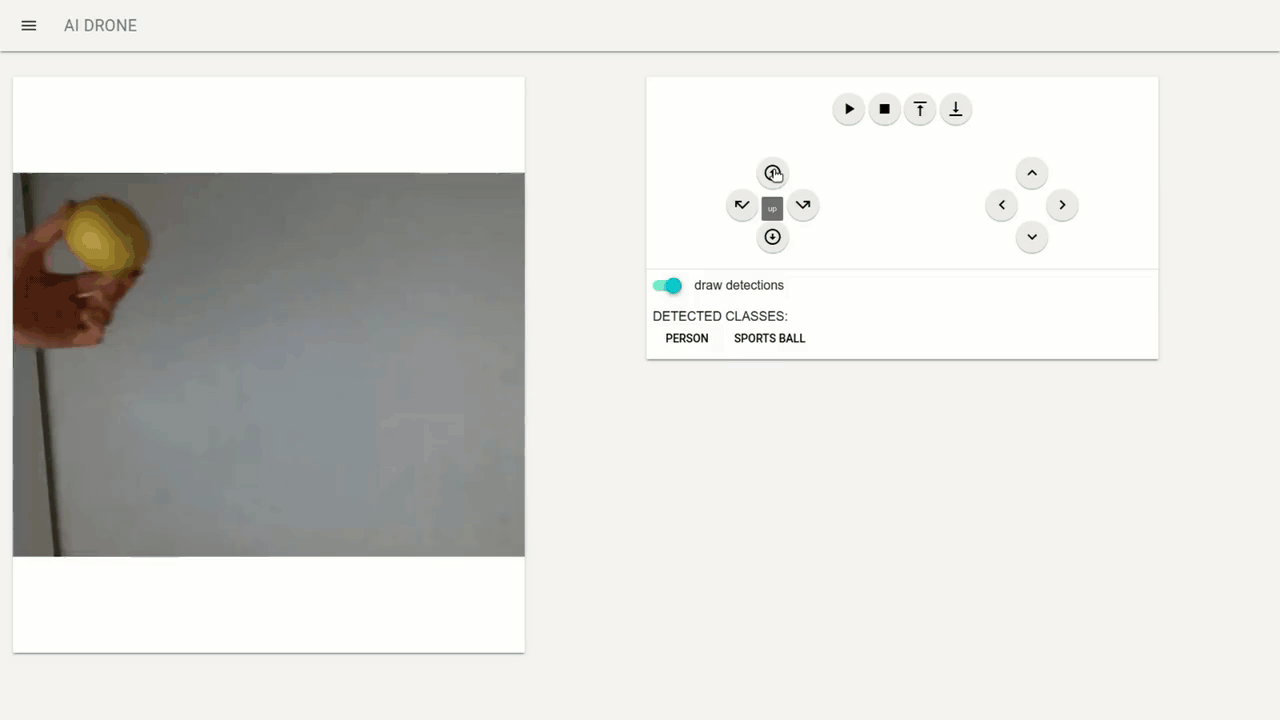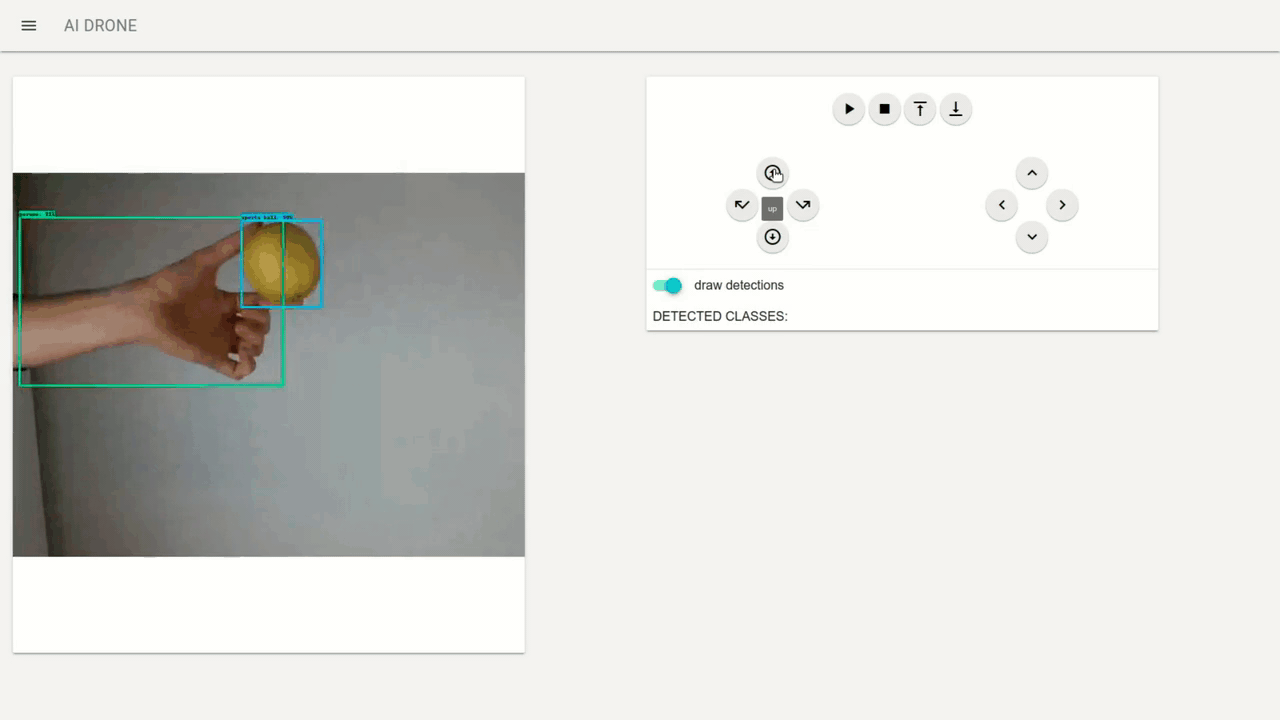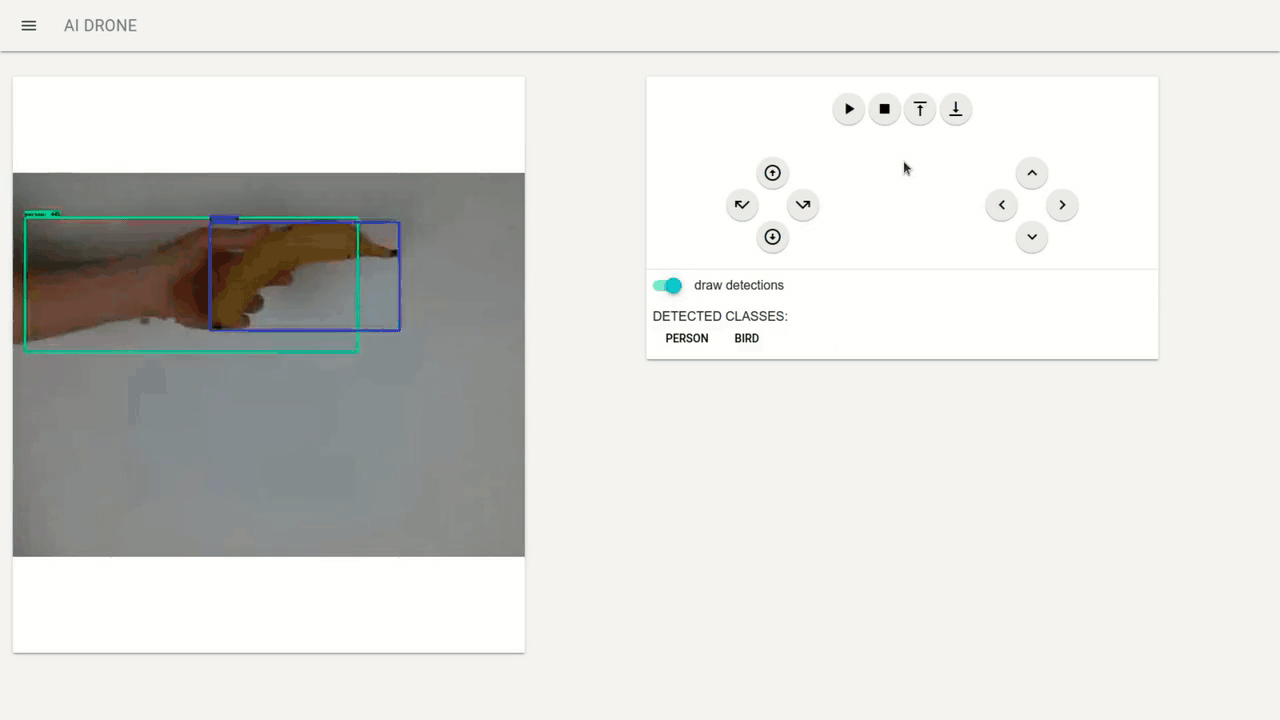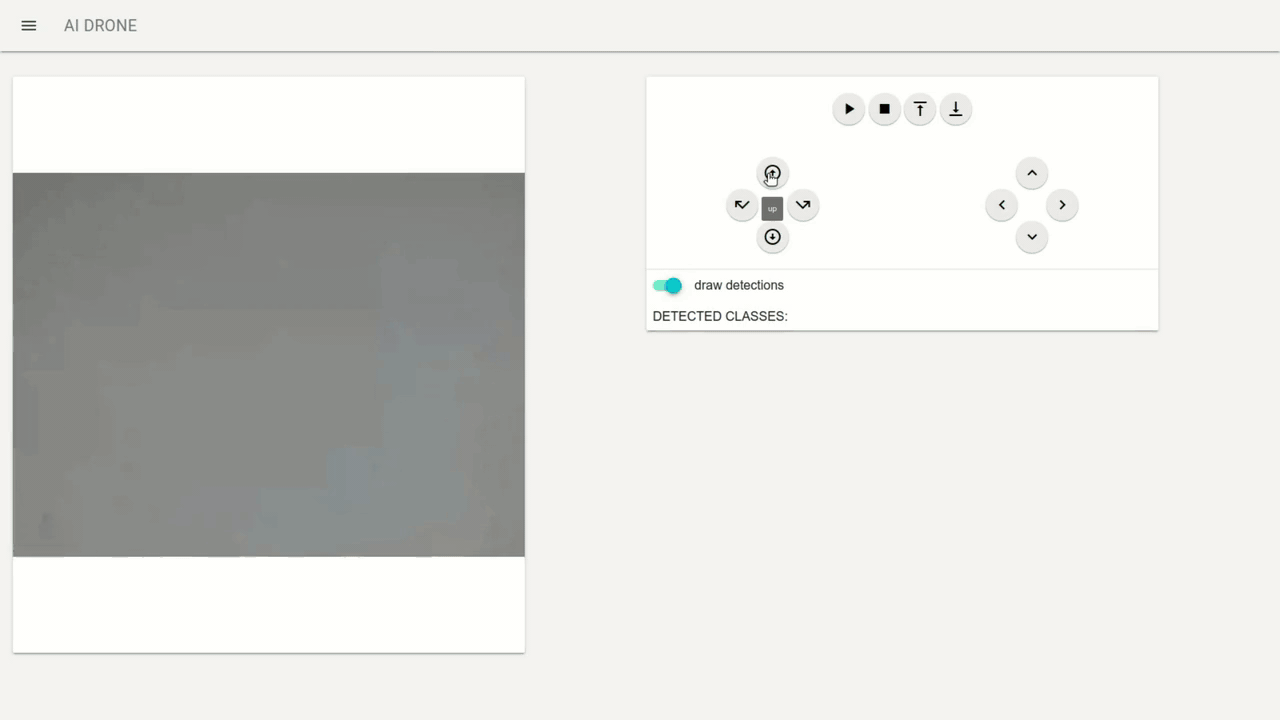
Using Web interface you can control the Tello movement where you can:
start video stream
stop video stream
takeoff - which starts Tello flight
land
up
down
rotate left
rotate right
forward
backward
left
right
In addition using draw detection switch you can turn on/off the detection boxes on the captured video stream (however this introduces a delay in the video thus it is turned off by default). Additionally I send the list of detected classes through web sockets which are also displayed.
As mentioned before I have used the pretrained model thus It is good idea to train your own model to get better results for narrower and more specific class of objects.
Finally the whole solution is packed into docker images thus you can simply start it using commands:
Machine Learning is one of the hottest area nowadays. New algorithms and models are widely used in commercial solutions thus the whole ML process as a software development and deployment process needs to be optimized.
On the other hand MLFlow is a platform which can be run as standalone application. It doesn’t require Kubernetes thus the setup much more simpler then Kubeflow but it doesn’t support multi-user/multi-team separation.
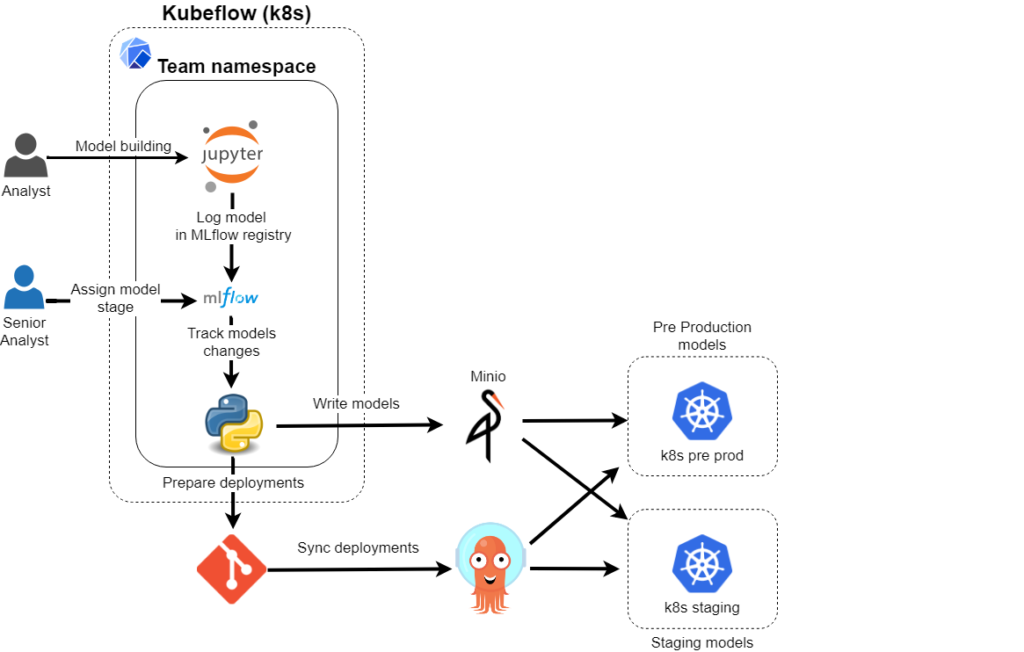
In this article we will use Kubeflow and MLflow to build the isolated workspace and MLOps pipelines for analytical teams.
Currently we use Kubeflow platform in @BankMillennium to build AI solutions and conduct MLOPS process and this article is inspired by the experience gained while launching and using the platform.
Before you will continue reading please watch short introduction:
AI Platform
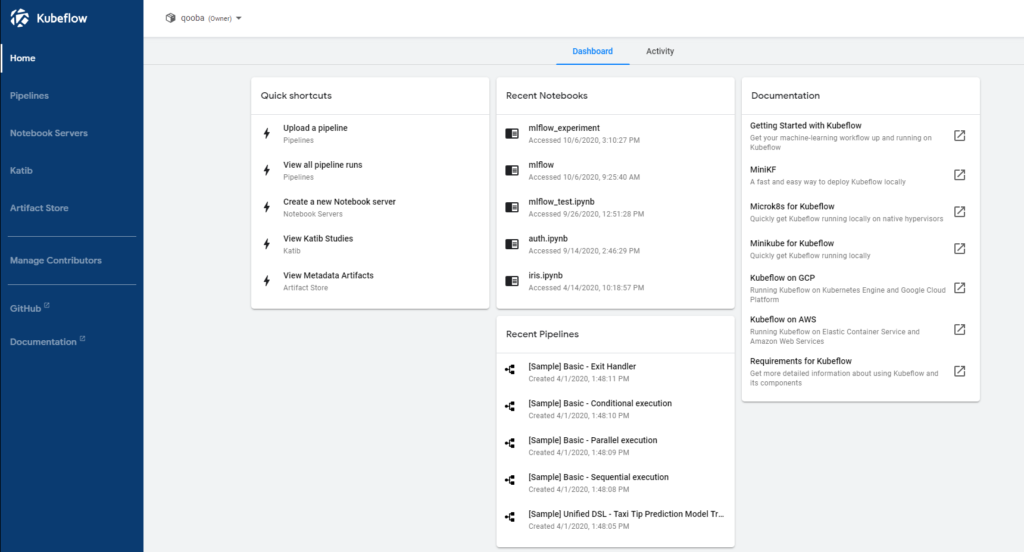
The core of the platform will be setup using Kubeflow (version 1.0.1) on Kubernetes (v1.17.0). The Kuberenetes was setup using Rancher RKE which simplifies the installation.
By default Kubeflow is equipped with metadata and artifact store shared between namespaces which makes it difficult to secure and organize spaces for teams. To fix this we will setup separate MLflow Tracking Server and Model Registry for each team namespace.
MLflow docker image qooba/mlflow:
FROM continuumio/miniconda3
RUN apt update && apt install python3-mysqldb default-libmysqlclient-dev -yq
RUN pip install mlflow sklearn jupyterlab watchdog[watchmedo] boto3
RUN conda install pymysql
ENV NB_PREFIX /
CMD ["sh","-c", "jupyter notebook --notebook-dir=/home/jovyan --ip=0.0.0.0 --no-browser --allow-root --port=8888 --NotebookApp.token='' --NotebookApp.password='' --NotebookApp.allow_origin='*' --NotebookApp.base_url=${NB_PREFIX}"]
import os
import warnings
import sys
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
from urllib.parse import urlparse
import mlflow
import mlflow.sklearn
import logging
remote_server_uri='http://mlflow:5000'
mlflow.set_tracking_uri(remote_server_uri)
mlflow.set_experiment("/my-experiment2")
logging.basicConfig(level=logging.WARN)
logger = logging.getLogger(__name__)
def eval_metrics(actual, pred):
rmse = np.sqrt(mean_squared_error(actual, pred))
mae = mean_absolute_error(actual, pred)
r2 = r2_score(actual, pred)
return rmse, mae, r2
warnings.filterwarnings("ignore")
np.random.seed(40)
# Read the wine-quality csv file from the URL
csv_url = (
"./winequality-red.csv"
)
try:
data = pd.read_csv(csv_url, sep=";")
except Exception as e:
logger.exception(
"Unable to download training & test CSV, check your internet connection. Error: %s", e
)
train, test = train_test_split(data)
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
alpha = 0.5
l1_ratio = 0.5
with mlflow.start_run():
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
print("Elasticnet model (alpha=%f, l1_ratio=%f):" % (alpha, l1_ratio))
print(" RMSE: %s" % rmse)
print(" MAE: %s" % mae)
print(" R2: %s" % r2)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
tracking_url_type_store = urlparse(mlflow.get_tracking_uri()).scheme
if tracking_url_type_store != "file":
mlflow.sklearn.log_model(lr, "model", registered_model_name="ElasticnetWineModel2")
else:
mlflow.sklearn.log_model(lr, "model")
I definitely recommend to use git versioned MLflow projects instead of running code directly from jupyter because
MLflow model registry will keep the git commit hash used for the run which will help to reproduce the results.
MLOps
Now I’d like to propose the process of building and deploying ML models.
Training
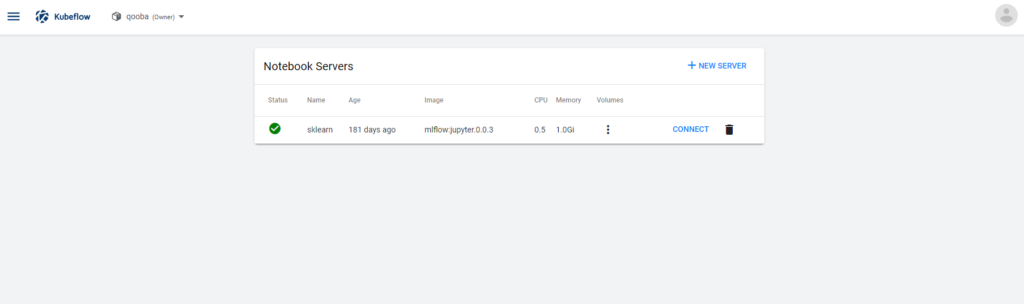
As described before the model is prepared and trained by the analyst which works in the Jupyter workspace and logs metrics and model to the MLflow tracking and model registry.
MLflow UI
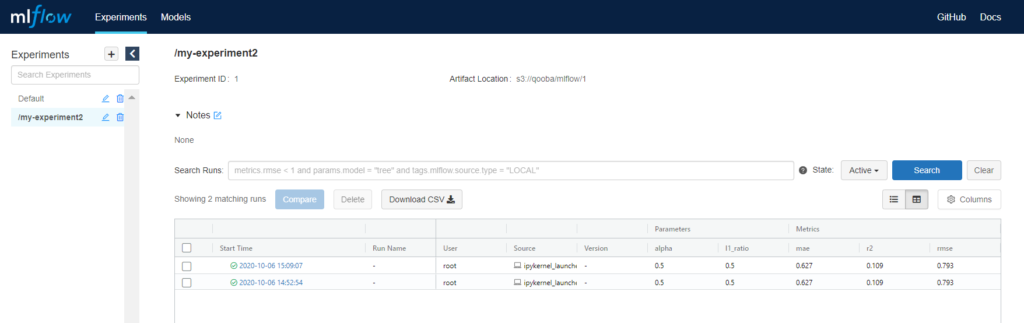
Senior Analyst (currently the MLflow doesn’t support roles assignment) checks the model metrics and decides to promote it to Staging/Production stage in MLflow UI.
Model promotion
We will create additional application which will track the changes in the MLflow registry and initialize the deployment process.
The on each MLflow registry change the python application will check the database, prepare and commit k8s deployments and upload models artifacts to minio.
Because the applications commits the deployments to git repository we need to generate ssh keys:
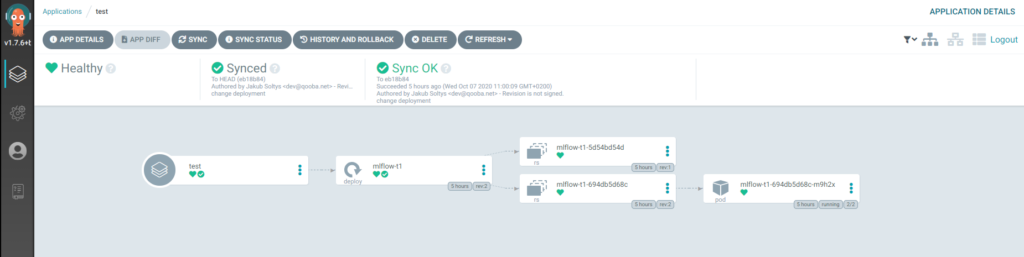
No it is time to setup ArgoCD which will sync the Git deployments changes with Kubernetes configuration and automatically deploy newly promoted models.
Each time new model is promoted the ArgoCD applies new deployment with the new model s3 path:
- name: MODEL
value: s3://qooba/mlflow/1/e0167f65abf4429b8c58f56b547fe514/artifacts/model
Inference services
Finally we can access model externally and generate predictions. Please note that in article the model is deployed in the same k8s namespace (in real solution model will be deployed on the separate k8s cluster) thus to access the model I have to send authservice_session otherwise request will redirected to the dex login page.
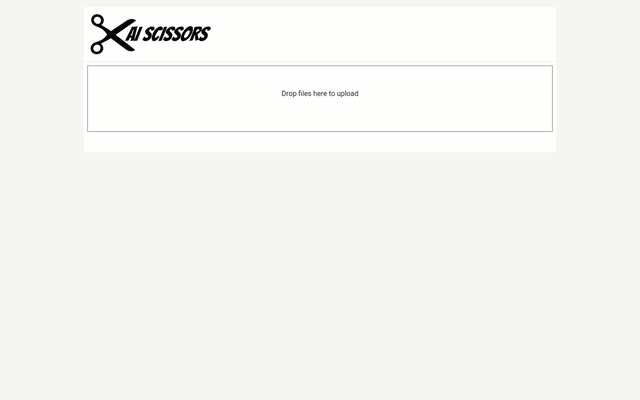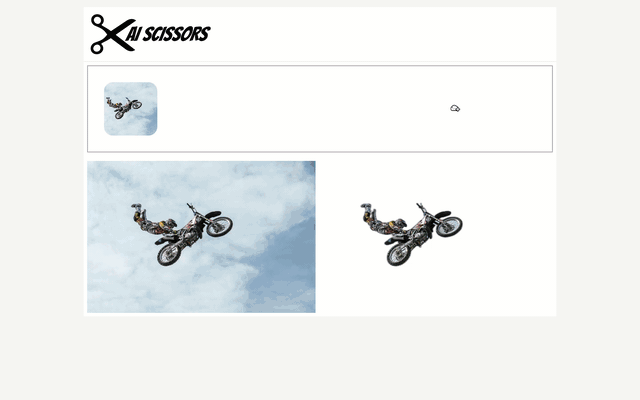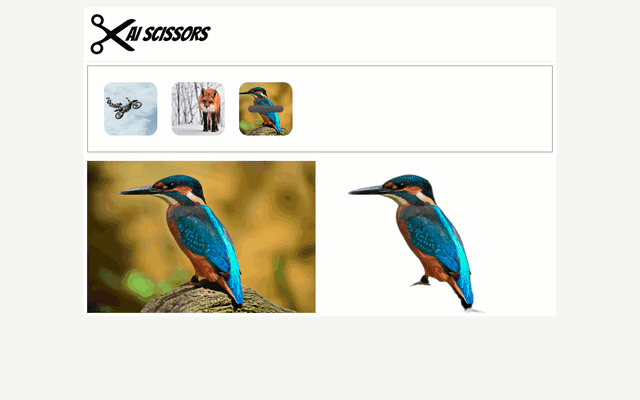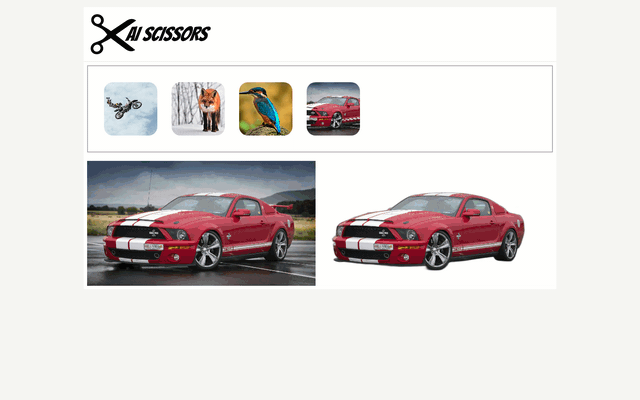
Cutting photos background is one of the most tedious graphical task. In this article will show how to simplify it using neural networks.
I will use U[latex]^2[/latex]-Net networks which are described in detail in the arxiv article and python library rembg to create ready to use drag and drop web application which you can use running docker image.
Before you will continue reading please watch quick introduction:
Neural network
To correctly remove the image background we need to select the most visually attractive objects in an image which is covered by Salient Object Detection (SOD). To connect a low memory and computation cost with competitive results against state of art methods the novel U[latex]^2[/latex]-Net architecture will be used.
U-Net convolutional networks have characteristic U shape with symmetric encoder-decoder structure. At each encoding stage the feature maps are downsampled (torch.nn.MaxPool2d) and then upsampled at each decoding
stage (torch.nn.functional.upsample). Downsample features are transferred and concatenated with upsample features using residual connections.
U[latex]^2[/latex]-Net network uses two-level nested U-structure where the main architecture is a U-Net like encoder-decoder and each stage contains residual U-block. Each residual U-block repeats donwsampling/upsampling procedures which are also connected using residual connections.
Nested U-structure extracts and aggregates the features at each level and enables to capture local and global information from shallow and deep layers.
The U[latex]^2[/latex]-Net architecture is precisely described in arxiv article. Moreover we can go through the pytorch model definition of U2NET and U2NETP.
The lighter U2NETP version is only 4.7 MB thus it can be used in mobile applications.
Web application
The neural network is wrapped with rembg library which automatically download pretrained networks and gives simple python api. To simplify the usage I have decided to create drag and drop web application (https://github.com/qooba/aiscissors)
In the application you can drag and the drop the image and then compare image with and without background side by side.
You can simply run the application using docker image:
docker run --gpus all --name aiscissors -d -p 8000:8000 --rm -v $(pwd)/u2net_models:/root/.u2net qooba/aiscissors
To use GPU additional nvidia drivers (included in the NVIDIA CUDA Toolkit) are needed.
When you run the container the pretrained models are downloaded thus I have mount local directory u2net_models to /root/.u2net to avoid download each time I run the container.
U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection, Qin, Xuebin and Zhang, Zichen and Huang, Chenyang and Dehghan, Masood and Zaiane, Osmar and Jagersand, Martin Pattern Recognition 106 107404 (2020)
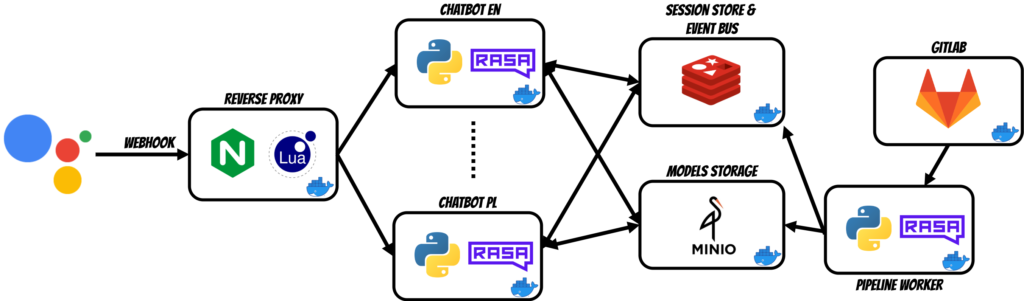
In this article I will show how to build the complete CI/CD solution for building, training and deploying multilingual chatbots.
I will use Rasa core framework, Gitlab pipelines, Minio and Redis to build simple two language google assistant.
Before you will continue reading please watch quick introduction:
Architecture
The solution contains several components thus I will describe each of them.
Google actions
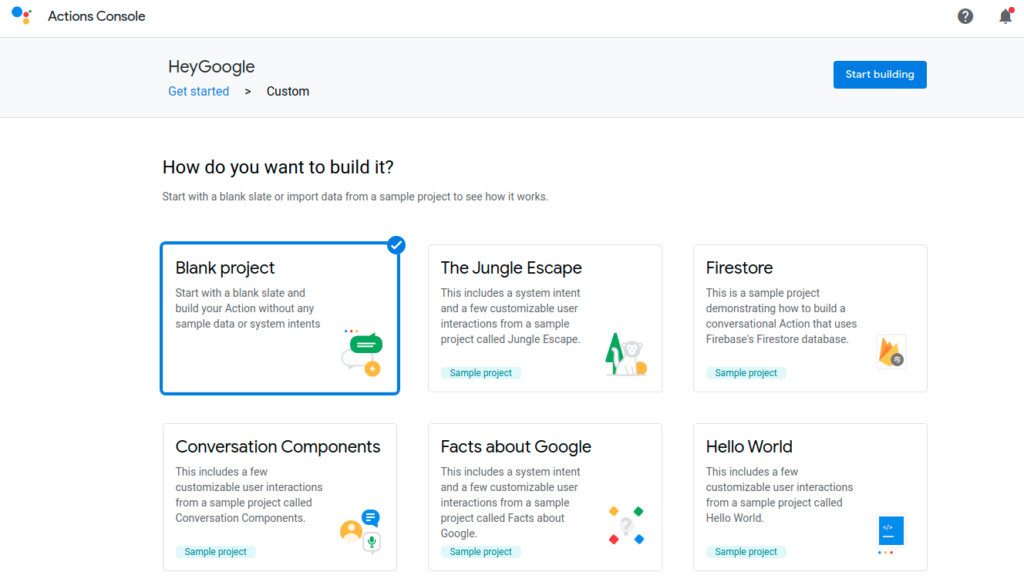
To build google assistant we need to create and configure the google action project.
We will build our own nlu engine thus we will start with the blank project.
Then we need to install gactions CLI to manage project from command line.
To access your projects you need to authenticate using command:
gactions login
if you want you can create the project using templates:
As mentioned before for development purposes I have used the ngrok to proxy the traffic from public endpoint (used for webhook destination) to localhost:8081:
ngrok http 8081
NGINX with LuaJIT
Currently in google action project is not possible to set different webhook addresses for different languages thus I have used NGINX and LuaJIT to route the traffic to proper language container.
The information about language context is included in the request body which can be handled using Lua script:
server {
listen 80;
resolver 127.0.0.11 ipv6=off;
location / {
set $target '';
access_by_lua '
local cjson = require("cjson")
ngx.req.read_body()
local text = ngx.var.request_body
local value = cjson.new().decode(text)
local lang = string.sub(value["user"]["locale"],1,2)
ngx.var.target = "http://heygoogle-" .. lang
';
proxy_pass $target;
}
}
Rasa application
The rasa core is one of the famous framework for building chatbots. I have decided to create separate docker container for each language which gives flexibility in terms of scalability and deployment.
Dockerfile (development version with watchdog) for rasa application (qooba/rasa:1.10.10_app):
FROM rasa/rasa:1.10.10
USER root
RUN pip3 install python-jose watchdog[watchmedo]
ENTRYPOINT watchmedo auto-restart -d . -p '*.py' --recursive -- python3 app.py
Using default rasa engine you have to restart the container when you want to deploy new retrained model thus I have decided to wrap it with simple python application which additionally listen the redis PubSub topic and waits for event which automatically reloads the model without restarting the whole application. Additionally there are separate topics for different languages thus we can simply deploy and reload model for specific language.
Redis
In this solution the redis has two responsibilities:
EventBus - as mentioned above chatbot app listen events sent from GitLab pipeline worker.
Session Store - which keeps the conversations state thus we can simply scale the chatbots
We can simply run Redis using command:
docker run --name redis -d --rm --network gitlab redis
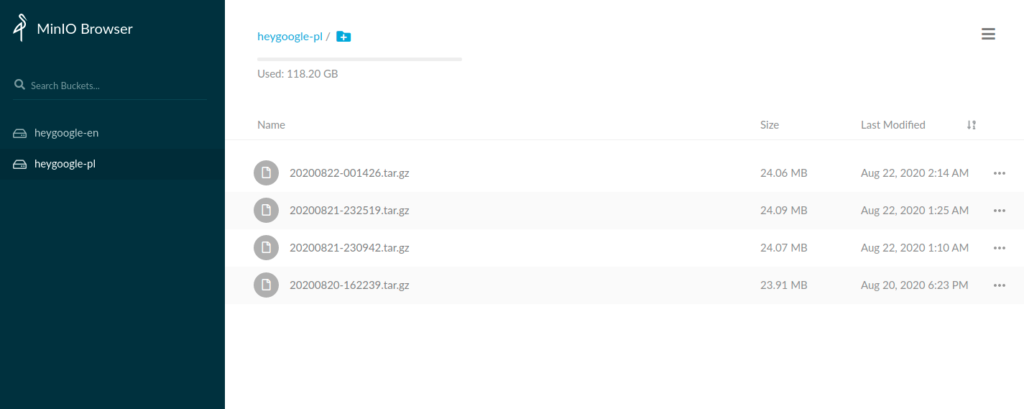
Minio
Minio is used as a Rasa Model Store (Rasa supports the S3 protocol). The GitLab pipeline worker after model training uploads the model package to Minio. Each language has separate bucket:
To run minio we will use command (for whole solution setup use run.sh where environment variables are set) :
Notice that I have used gitlab hostname (without this pipelines does not work correctly on localhost) thus you will need to add appropriate entry to /etc/hosts:
127.0.1.1 gitlab
Now you can create new project (in my case I called it heygoogle).
Likely you already use 22 port thus for ssh I used 8022.
You can clone the project using command (remember to setup ssh keys):
#!/bin/bash
lang=$1
echo "Processing $lang"
if (($(git diff-tree --no-commit-id --name-only -r $CI_COMMIT_SHA | grep ^$lang/ | wc -l) > 0)); then
echo "Training $lang"
cd $lang
rasa train
rasa test
cd ..
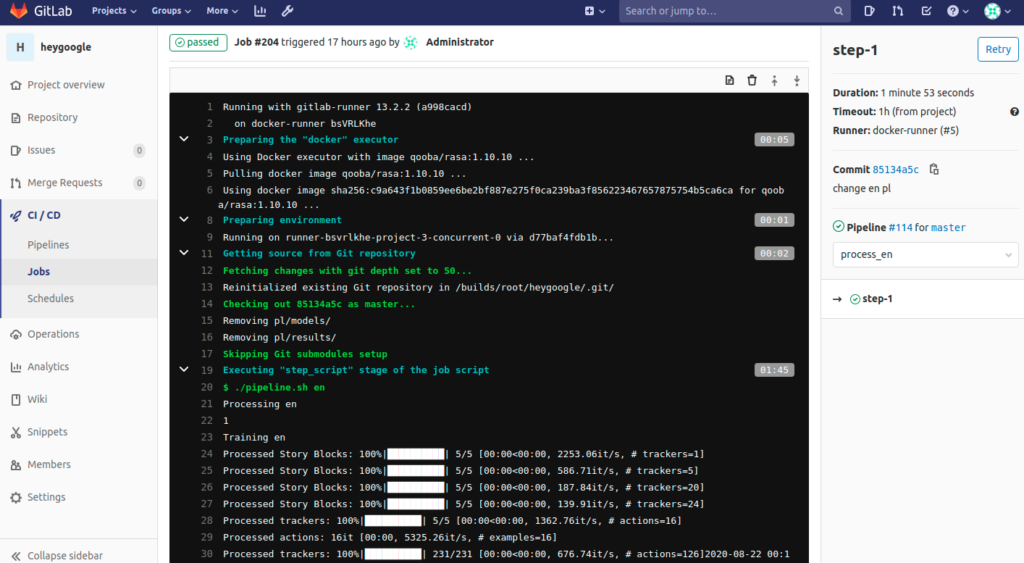
python3 pipeline.py --language $lang
else
echo
checks if something have changed in chosen language directory, trains and tests the model
and finally uploads trained model to Minio and publish event to Redis using
pipeline.py:
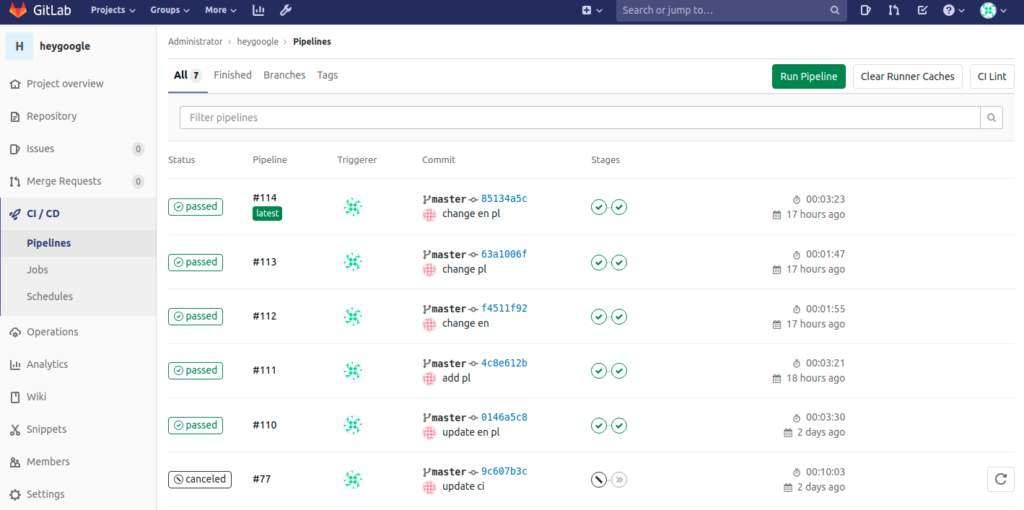
Now after each change in the repository the gitlab starts the pipeline run:
Summary
We have built complete solution for creating, training, testing and deploying the chatbots.
Additionally the solution supports multi language chatbots keeping scalability and deployment flexibility.
Moreover trained models can be continuously deployed without chatbot downtime (for Kubernetes environments
the Canary Deployment could be another solution).
Finally we have integrated solution with the google actions and created simple chatbot.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.Ok